 -
-
-
-
-
-  -
-
-## Installation
-
-```bash
-pip install annotated-doc
-```
-
-Or with `uv`:
-
-```Python
-uv add annotated-doc
-```
-
-## Usage
-
-Import `Doc` and pass a single literal string with the documentation for the specific parameter, class attribute, return type, or variable.
-
-For example, to document a parameter `name` in a function `hi` you could do:
-
-```Python
-from typing import Annotated
-
-from annotated_doc import Doc
-
-def hi(name: Annotated[str, Doc("Who to say hi to")]) -> None:
- print(f"Hi, {name}!")
-```
-
-You can also use it to document class attributes:
-
-```Python
-from typing import Annotated
-
-from annotated_doc import Doc
-
-class User:
- name: Annotated[str, Doc("The user's name")]
- age: Annotated[int, Doc("The user's age")]
-```
-
-The same way, you could document return types and variables, or anything that could have a type annotation with `Annotated`.
-
-## Who Uses This
-
-`annotated-doc` was made for:
-
-* [FastAPI](https://fastapi.tiangolo.com/)
-* [Typer](https://typer.tiangolo.com/)
-* [SQLModel](https://sqlmodel.tiangolo.com/)
-* [Asyncer](https://asyncer.tiangolo.com/)
-
-`annotated-doc` is supported by [griffe-typingdoc](https://github.com/mkdocstrings/griffe-typingdoc), which powers reference documentation like the one in the [FastAPI Reference](https://fastapi.tiangolo.com/reference/).
-
-## Reasons not to use `annotated-doc`
-
-You are already comfortable with one of the existing docstring formats, like:
-
-* Sphinx
-* numpydoc
-* Google
-* Keras
-
-Your team is already comfortable using them.
-
-You prefer having the documentation about parameters all together in a docstring, separated from the code defining them.
-
-You care about a specific set of users, using one specific editor, and that editor already has support for the specific docstring format you use.
-
-## Reasons to use `annotated-doc`
-
-* No micro-syntax to learn for newcomers, it’s **just Python** syntax.
-* **Editing** would be already fully supported by default by any editor (current or future) supporting Python syntax, including syntax errors, syntax highlighting, etc.
-* **Rendering** would be relatively straightforward to implement by static tools (tools that don't need runtime execution), as the information can be extracted from the AST they normally already create.
-* **Deduplication of information**: the name of a parameter would be defined in a single place, not duplicated inside of a docstring.
-* **Elimination** of the possibility of having **inconsistencies** when removing a parameter or class variable and **forgetting to remove** its documentation.
-* **Minimization** of the probability of adding a new parameter or class variable and **forgetting to add its documentation**.
-* **Elimination** of the possibility of having **inconsistencies** between the **name** of a parameter in the **signature** and the name in the docstring when it is renamed.
-* **Access** to the documentation string for each symbol at **runtime**, including existing (older) Python versions.
-* A more formalized way to document other symbols, like type aliases, that could use Annotated.
-* **Support** for apps using FastAPI, Typer and others.
-* **AI Accessibility**: AI tools will have an easier way understanding each parameter as the distance from documentation to parameter is much closer.
-
-## History
-
-I ([@tiangolo](https://github.com/tiangolo)) originally wanted for this to be part of the Python standard library (in [PEP 727](https://peps.python.org/pep-0727/)), but the proposal was withdrawn as there was a fair amount of negative feedback and opposition.
-
-The conclusion was that this was better done as an external effort, in a third-party library.
-
-So, here it is, with a simpler approach, as a third-party library, in a way that can be used by others, starting with FastAPI and friends.
-
-## License
-
-This project is licensed under the terms of the MIT license.
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD
deleted file mode 100644
index 06bbc8d..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD
+++ /dev/null
@@ -1,11 +0,0 @@
-annotated_doc-0.0.4.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
-annotated_doc-0.0.4.dist-info/METADATA,sha256=Irm5KJua33dY2qKKAjJ-OhKaVBVIfwFGej_dSe3Z1TU,6566
-annotated_doc-0.0.4.dist-info/RECORD,,
-annotated_doc-0.0.4.dist-info/WHEEL,sha256=9P2ygRxDrTJz3gsagc0Z96ukrxjr-LFBGOgv3AuKlCA,90
-annotated_doc-0.0.4.dist-info/entry_points.txt,sha256=6OYgBcLyFCUgeqLgnvMyOJxPCWzgy7se4rLPKtNonMs,34
-annotated_doc-0.0.4.dist-info/licenses/LICENSE,sha256=__Fwd5pqy_ZavbQFwIfxzuF4ZpHkqWpANFF-SlBKDN8,1086
-annotated_doc/__init__.py,sha256=VuyxxUe80kfEyWnOrCx_Bk8hybo3aKo6RYBlkBBYW8k,52
-annotated_doc/__pycache__/__init__.cpython-312.pyc,,
-annotated_doc/__pycache__/main.cpython-312.pyc,,
-annotated_doc/main.py,sha256=5Zfvxv80SwwLqpRW73AZyZyiM4bWma9QWRbp_cgD20s,1075
-annotated_doc/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL
deleted file mode 100644
index 045c8ac..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL
+++ /dev/null
@@ -1,4 +0,0 @@
-Wheel-Version: 1.0
-Generator: pdm-backend (2.4.5)
-Root-Is-Purelib: true
-Tag: py3-none-any
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt
deleted file mode 100644
index c3ad472..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-[console_scripts]
-
-[gui_scripts]
-
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE
deleted file mode 100644
index 7a25446..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE
+++ /dev/null
@@ -1,21 +0,0 @@
-The MIT License (MIT)
-
-Copyright (c) 2025 Sebastián Ramírez
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in
-all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
-THE SOFTWARE.
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py
deleted file mode 100644
index a0152a7..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .main import Doc as Doc
-
-__version__ = "0.0.4"
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index acef568..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc
deleted file mode 100644
index 3f27881..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py b/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py
deleted file mode 100644
index 7063c59..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py
+++ /dev/null
@@ -1,36 +0,0 @@
-class Doc:
- """Define the documentation of a type annotation using `Annotated`, to be
- used in class attributes, function and method parameters, return values,
- and variables.
-
- The value should be a positional-only string literal to allow static tools
- like editors and documentation generators to use it.
-
- This complements docstrings.
-
- The string value passed is available in the attribute `documentation`.
-
- Example:
-
- ```Python
- from typing import Annotated
- from annotated_doc import Doc
-
- def hi(name: Annotated[str, Doc("Who to say hi to")]) -> None:
- print(f"Hi, {name}!")
- ```
- """
-
- def __init__(self, documentation: str, /) -> None:
- self.documentation = documentation
-
- def __repr__(self) -> str:
- return f"Doc({self.documentation!r})"
-
- def __hash__(self) -> int:
- return hash(self.documentation)
-
- def __eq__(self, other: object) -> bool:
- if not isinstance(other, Doc):
- return NotImplemented
- return self.documentation == other.documentation
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/py.typed b/backend/.venv/lib/python3.12/site-packages/annotated_doc/py.typed
deleted file mode 100644
index e69de29..0000000
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER b/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER
deleted file mode 100644
index a1b589e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER
+++ /dev/null
@@ -1 +0,0 @@
-pip
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA b/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA
deleted file mode 100644
index 3ac05cf..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA
+++ /dev/null
@@ -1,295 +0,0 @@
-Metadata-Version: 2.3
-Name: annotated-types
-Version: 0.7.0
-Summary: Reusable constraint types to use with typing.Annotated
-Project-URL: Homepage, https://github.com/annotated-types/annotated-types
-Project-URL: Source, https://github.com/annotated-types/annotated-types
-Project-URL: Changelog, https://github.com/annotated-types/annotated-types/releases
-Author-email: Adrian Garcia Badaracco <1755071+adriangb@users.noreply.github.com>, Samuel Colvin
-
-
-## Installation
-
-```bash
-pip install annotated-doc
-```
-
-Or with `uv`:
-
-```Python
-uv add annotated-doc
-```
-
-## Usage
-
-Import `Doc` and pass a single literal string with the documentation for the specific parameter, class attribute, return type, or variable.
-
-For example, to document a parameter `name` in a function `hi` you could do:
-
-```Python
-from typing import Annotated
-
-from annotated_doc import Doc
-
-def hi(name: Annotated[str, Doc("Who to say hi to")]) -> None:
- print(f"Hi, {name}!")
-```
-
-You can also use it to document class attributes:
-
-```Python
-from typing import Annotated
-
-from annotated_doc import Doc
-
-class User:
- name: Annotated[str, Doc("The user's name")]
- age: Annotated[int, Doc("The user's age")]
-```
-
-The same way, you could document return types and variables, or anything that could have a type annotation with `Annotated`.
-
-## Who Uses This
-
-`annotated-doc` was made for:
-
-* [FastAPI](https://fastapi.tiangolo.com/)
-* [Typer](https://typer.tiangolo.com/)
-* [SQLModel](https://sqlmodel.tiangolo.com/)
-* [Asyncer](https://asyncer.tiangolo.com/)
-
-`annotated-doc` is supported by [griffe-typingdoc](https://github.com/mkdocstrings/griffe-typingdoc), which powers reference documentation like the one in the [FastAPI Reference](https://fastapi.tiangolo.com/reference/).
-
-## Reasons not to use `annotated-doc`
-
-You are already comfortable with one of the existing docstring formats, like:
-
-* Sphinx
-* numpydoc
-* Google
-* Keras
-
-Your team is already comfortable using them.
-
-You prefer having the documentation about parameters all together in a docstring, separated from the code defining them.
-
-You care about a specific set of users, using one specific editor, and that editor already has support for the specific docstring format you use.
-
-## Reasons to use `annotated-doc`
-
-* No micro-syntax to learn for newcomers, it’s **just Python** syntax.
-* **Editing** would be already fully supported by default by any editor (current or future) supporting Python syntax, including syntax errors, syntax highlighting, etc.
-* **Rendering** would be relatively straightforward to implement by static tools (tools that don't need runtime execution), as the information can be extracted from the AST they normally already create.
-* **Deduplication of information**: the name of a parameter would be defined in a single place, not duplicated inside of a docstring.
-* **Elimination** of the possibility of having **inconsistencies** when removing a parameter or class variable and **forgetting to remove** its documentation.
-* **Minimization** of the probability of adding a new parameter or class variable and **forgetting to add its documentation**.
-* **Elimination** of the possibility of having **inconsistencies** between the **name** of a parameter in the **signature** and the name in the docstring when it is renamed.
-* **Access** to the documentation string for each symbol at **runtime**, including existing (older) Python versions.
-* A more formalized way to document other symbols, like type aliases, that could use Annotated.
-* **Support** for apps using FastAPI, Typer and others.
-* **AI Accessibility**: AI tools will have an easier way understanding each parameter as the distance from documentation to parameter is much closer.
-
-## History
-
-I ([@tiangolo](https://github.com/tiangolo)) originally wanted for this to be part of the Python standard library (in [PEP 727](https://peps.python.org/pep-0727/)), but the proposal was withdrawn as there was a fair amount of negative feedback and opposition.
-
-The conclusion was that this was better done as an external effort, in a third-party library.
-
-So, here it is, with a simpler approach, as a third-party library, in a way that can be used by others, starting with FastAPI and friends.
-
-## License
-
-This project is licensed under the terms of the MIT license.
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD
deleted file mode 100644
index 06bbc8d..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/RECORD
+++ /dev/null
@@ -1,11 +0,0 @@
-annotated_doc-0.0.4.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
-annotated_doc-0.0.4.dist-info/METADATA,sha256=Irm5KJua33dY2qKKAjJ-OhKaVBVIfwFGej_dSe3Z1TU,6566
-annotated_doc-0.0.4.dist-info/RECORD,,
-annotated_doc-0.0.4.dist-info/WHEEL,sha256=9P2ygRxDrTJz3gsagc0Z96ukrxjr-LFBGOgv3AuKlCA,90
-annotated_doc-0.0.4.dist-info/entry_points.txt,sha256=6OYgBcLyFCUgeqLgnvMyOJxPCWzgy7se4rLPKtNonMs,34
-annotated_doc-0.0.4.dist-info/licenses/LICENSE,sha256=__Fwd5pqy_ZavbQFwIfxzuF4ZpHkqWpANFF-SlBKDN8,1086
-annotated_doc/__init__.py,sha256=VuyxxUe80kfEyWnOrCx_Bk8hybo3aKo6RYBlkBBYW8k,52
-annotated_doc/__pycache__/__init__.cpython-312.pyc,,
-annotated_doc/__pycache__/main.cpython-312.pyc,,
-annotated_doc/main.py,sha256=5Zfvxv80SwwLqpRW73AZyZyiM4bWma9QWRbp_cgD20s,1075
-annotated_doc/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL
deleted file mode 100644
index 045c8ac..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/WHEEL
+++ /dev/null
@@ -1,4 +0,0 @@
-Wheel-Version: 1.0
-Generator: pdm-backend (2.4.5)
-Root-Is-Purelib: true
-Tag: py3-none-any
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt
deleted file mode 100644
index c3ad472..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/entry_points.txt
+++ /dev/null
@@ -1,4 +0,0 @@
-[console_scripts]
-
-[gui_scripts]
-
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE b/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE
deleted file mode 100644
index 7a25446..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc-0.0.4.dist-info/licenses/LICENSE
+++ /dev/null
@@ -1,21 +0,0 @@
-The MIT License (MIT)
-
-Copyright (c) 2025 Sebastián Ramírez
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in
-all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
-THE SOFTWARE.
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py
deleted file mode 100644
index a0152a7..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .main import Doc as Doc
-
-__version__ = "0.0.4"
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index acef568..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc
deleted file mode 100644
index 3f27881..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/annotated_doc/__pycache__/main.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py b/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py
deleted file mode 100644
index 7063c59..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_doc/main.py
+++ /dev/null
@@ -1,36 +0,0 @@
-class Doc:
- """Define the documentation of a type annotation using `Annotated`, to be
- used in class attributes, function and method parameters, return values,
- and variables.
-
- The value should be a positional-only string literal to allow static tools
- like editors and documentation generators to use it.
-
- This complements docstrings.
-
- The string value passed is available in the attribute `documentation`.
-
- Example:
-
- ```Python
- from typing import Annotated
- from annotated_doc import Doc
-
- def hi(name: Annotated[str, Doc("Who to say hi to")]) -> None:
- print(f"Hi, {name}!")
- ```
- """
-
- def __init__(self, documentation: str, /) -> None:
- self.documentation = documentation
-
- def __repr__(self) -> str:
- return f"Doc({self.documentation!r})"
-
- def __hash__(self) -> int:
- return hash(self.documentation)
-
- def __eq__(self, other: object) -> bool:
- if not isinstance(other, Doc):
- return NotImplemented
- return self.documentation == other.documentation
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_doc/py.typed b/backend/.venv/lib/python3.12/site-packages/annotated_doc/py.typed
deleted file mode 100644
index e69de29..0000000
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER b/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER
deleted file mode 100644
index a1b589e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/INSTALLER
+++ /dev/null
@@ -1 +0,0 @@
-pip
diff --git a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA b/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA
deleted file mode 100644
index 3ac05cf..0000000
--- a/backend/.venv/lib/python3.12/site-packages/annotated_types-0.7.0.dist-info/METADATA
+++ /dev/null
@@ -1,295 +0,0 @@
-Metadata-Version: 2.3
-Name: annotated-types
-Version: 0.7.0
-Summary: Reusable constraint types to use with typing.Annotated
-Project-URL: Homepage, https://github.com/annotated-types/annotated-types
-Project-URL: Source, https://github.com/annotated-types/annotated-types
-Project-URL: Changelog, https://github.com/annotated-types/annotated-types/releases
-Author-email: Adrian Garcia Badaracco <1755071+adriangb@users.noreply.github.com>, Samuel Colvin 
- ![]() -
-
- FastAPI framework, high performance, easy to learn, fast to code, ready for production -
- - ---- - -**Documentation**: https://fastapi.tiangolo.com - -**Source Code**: https://github.com/fastapi/fastapi - ---- - -FastAPI is a modern, fast (high-performance), web framework for building APIs with Python based on standard Python type hints. - -The key features are: - -* **Fast**: Very high performance, on par with **NodeJS** and **Go** (thanks to Starlette and Pydantic). [One of the fastest Python frameworks available](#performance). -* **Fast to code**: Increase the speed to develop features by about 200% to 300%. * -* **Fewer bugs**: Reduce about 40% of human (developer) induced errors. * -* **Intuitive**: Great editor support. Completion everywhere. Less time debugging. -* **Easy**: Designed to be easy to use and learn. Less time reading docs. -* **Short**: Minimize code duplication. Multiple features from each parameter declaration. Fewer bugs. -* **Robust**: Get production-ready code. With automatic interactive documentation. -* **Standards-based**: Based on (and fully compatible with) the open standards for APIs: OpenAPI (previously known as Swagger) and JSON Schema. - -* estimation based on tests conducted by an internal development team, building production applications. - -## Sponsors - - -### Keystone Sponsor - - -
- -
- -
-### Gold and Silver Sponsors
-
-
-
-### Gold and Silver Sponsors
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-
-
-Other sponsors
-
-## Opinions
-
-"_[...] I'm using **FastAPI** a ton these days. [...] I'm actually planning to use it for all of my team's **ML services at Microsoft**. Some of them are getting integrated into the core **Windows** product and some **Office** products._"
-
-
-
-
-
-Other sponsors
-
-## Opinions
-
-"_[...] I'm using **FastAPI** a ton these days. [...] I'm actually planning to use it for all of my team's **ML services at Microsoft**. Some of them are getting integrated into the core **Windows** product and some **Office** products._"
-
-Kabir Khan - Microsoft (ref)
-
----
-
-"_We adopted the **FastAPI** library to spawn a **REST** server that can be queried to obtain **predictions**. [for Ludwig]_"
-
-Piero Molino, Yaroslav Dudin, and Sai Sumanth Miryala - Uber (ref)
-
----
-
-"_**Netflix** is pleased to announce the open-source release of our **crisis management** orchestration framework: **Dispatch**! [built with **FastAPI**]_"
-
-Kevin Glisson, Marc Vilanova, Forest Monsen - Netflix (ref)
-
----
-
-"_I’m over the moon excited about **FastAPI**. It’s so fun!_"
-
-Brian Okken - Python Bytes podcast host (ref)
-
----
-
-"_Honestly, what you've built looks super solid and polished. In many ways, it's what I wanted **Hug** to be - it's really inspiring to see someone build that._"
-
-
-
----
-
-"_If you're looking to learn one **modern framework** for building REST APIs, check out **FastAPI** [...] It's fast, easy to use and easy to learn [...]_"
-
-"_We've switched over to **FastAPI** for our **APIs** [...] I think you'll like it [...]_"
-
-
-
----
-
-"_If anyone is looking to build a production Python API, I would highly recommend **FastAPI**. It is **beautifully designed**, **simple to use** and **highly scalable**, it has become a **key component** in our API first development strategy and is driving many automations and services such as our Virtual TAC Engineer._"
-
-Deon Pillsbury - Cisco (ref)
-
----
-
-## FastAPI mini documentary
-
-There's a FastAPI mini documentary released at the end of 2025, you can watch it online:
-
- -
-## **Typer**, the FastAPI of CLIs
-
-
-
-## **Typer**, the FastAPI of CLIs
-
-
-
-```console
-$ pip install "fastapi[standard]"
-
----> 100%
-```
-
-
-
-**Note**: Make sure you put `"fastapi[standard]"` in quotes to ensure it works in all terminals.
-
-## Example
-
-### Create it
-
-Create a file `main.py` with:
-
-```Python
-from typing import Union
-
-from fastapi import FastAPI
-
-app = FastAPI()
-
-
-@app.get("/")
-def read_root():
- return {"Hello": "World"}
-
-
-@app.get("/items/{item_id}")
-def read_item(item_id: int, q: Union[str, None] = None):
- return {"item_id": item_id, "q": q}
-```
-
-
-Or use
-
-If your code uses `async` / `await`, use `async def`:
-
-```Python hl_lines="9 14"
-from typing import Union
-
-from fastapi import FastAPI
-
-app = FastAPI()
-
-
-@app.get("/")
-async def read_root():
- return {"Hello": "World"}
-
-
-@app.get("/items/{item_id}")
-async def read_item(item_id: int, q: Union[str, None] = None):
- return {"item_id": item_id, "q": q}
-```
-
-**Note**:
-
-If you don't know, check the _"In a hurry?"_ section about `async` and `await` in the docs.
-
-
-
-### Run it
-
-Run the server with:
-
-Or use async def...
-
-If your code uses `async` / `await`, use `async def`:
-
-```Python hl_lines="9 14"
-from typing import Union
-
-from fastapi import FastAPI
-
-app = FastAPI()
-
-
-@app.get("/")
-async def read_root():
- return {"Hello": "World"}
-
-
-@app.get("/items/{item_id}")
-async def read_item(item_id: int, q: Union[str, None] = None):
- return {"item_id": item_id, "q": q}
-```
-
-**Note**:
-
-If you don't know, check the _"In a hurry?"_ section about `async` and `await` in the docs.
-
-
-
-```console
-$ fastapi dev main.py
-
- ╭────────── FastAPI CLI - Development mode ───────────╮
- │ │
- │ Serving at: http://127.0.0.1:8000 │
- │ │
- │ API docs: http://127.0.0.1:8000/docs │
- │ │
- │ Running in development mode, for production use: │
- │ │
- │ fastapi run │
- │ │
- ╰─────────────────────────────────────────────────────╯
-
-INFO: Will watch for changes in these directories: ['/home/user/code/awesomeapp']
-INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
-INFO: Started reloader process [2248755] using WatchFiles
-INFO: Started server process [2248757]
-INFO: Waiting for application startup.
-INFO: Application startup complete.
-```
-
-
-
-
-About the command
-
-The command `fastapi dev` reads your `main.py` file, detects the **FastAPI** app in it, and starts a server using Uvicorn.
-
-By default, `fastapi dev` will start with auto-reload enabled for local development.
-
-You can read more about it in the FastAPI CLI docs.
-
-
-
-### Check it
-
-Open your browser at http://127.0.0.1:8000/items/5?q=somequery.
-
-You will see the JSON response as:
-
-```JSON
-{"item_id": 5, "q": "somequery"}
-```
-
-You already created an API that:
-
-* Receives HTTP requests in the _paths_ `/` and `/items/{item_id}`.
-* Both _paths_ take `GET` operations (also known as HTTP _methods_).
-* The _path_ `/items/{item_id}` has a _path parameter_ `item_id` that should be an `int`.
-* The _path_ `/items/{item_id}` has an optional `str` _query parameter_ `q`.
-
-### Interactive API docs
-
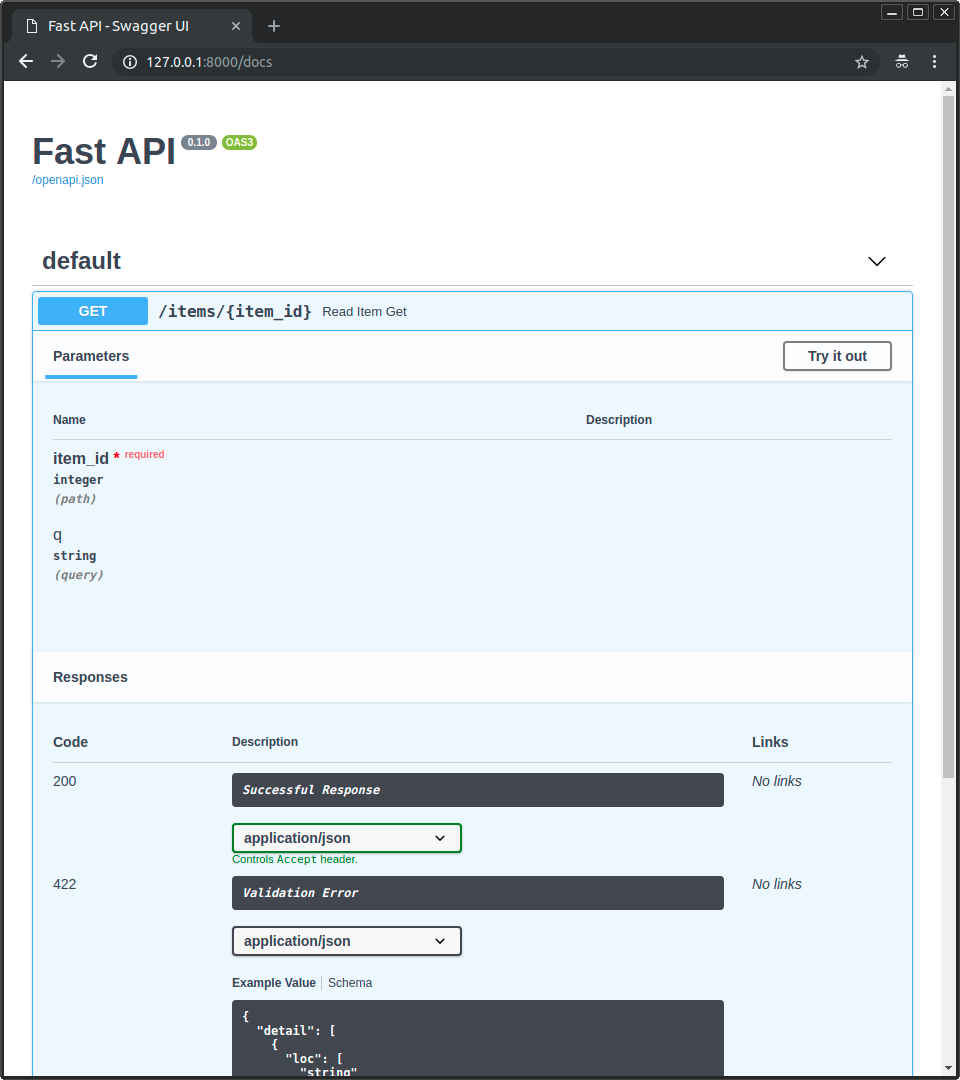
-Now go to http://127.0.0.1:8000/docs.
-
-You will see the automatic interactive API documentation (provided by Swagger UI):
-
-
-
-### Alternative API docs
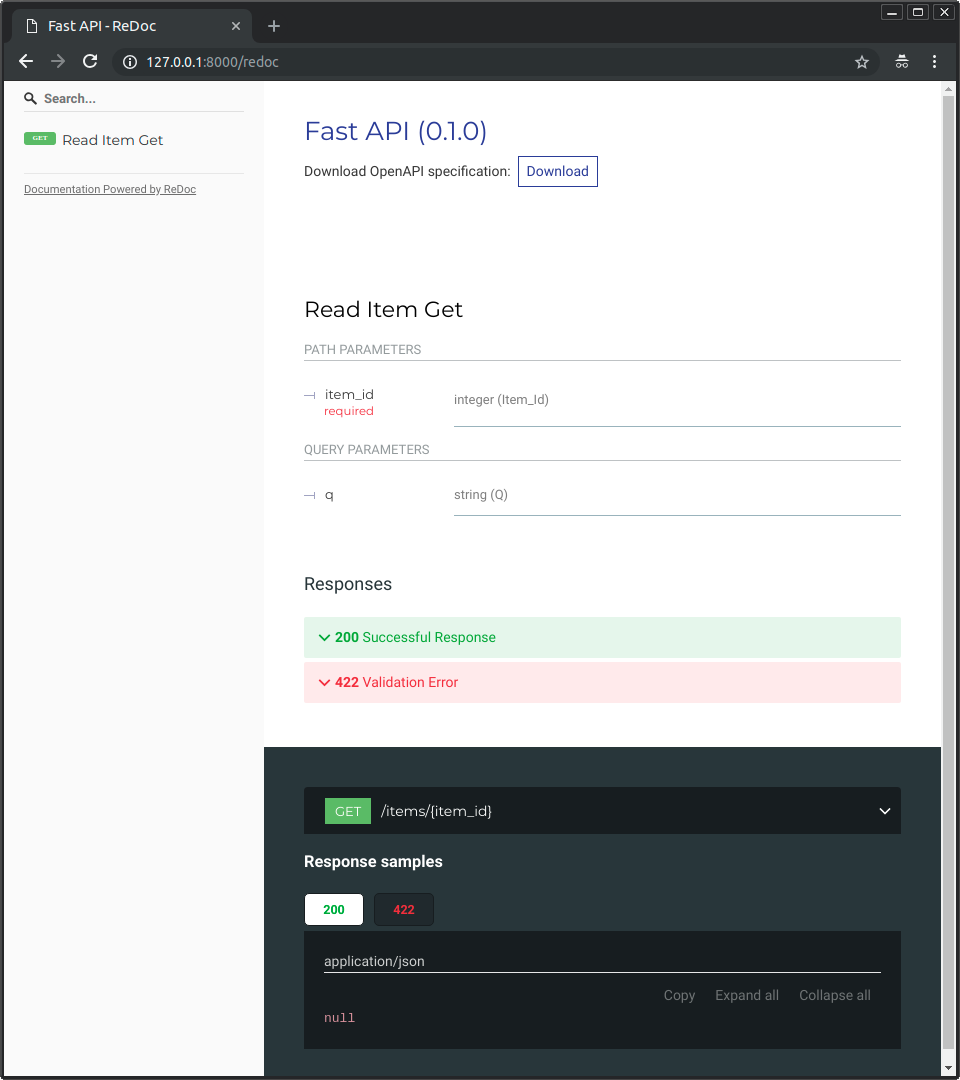
-
-And now, go to http://127.0.0.1:8000/redoc.
-
-You will see the alternative automatic documentation (provided by ReDoc):
-
-
-
-## Example upgrade
-
-Now modify the file `main.py` to receive a body from a `PUT` request.
-
-Declare the body using standard Python types, thanks to Pydantic.
-
-```Python hl_lines="4 9-12 25-27"
-from typing import Union
-
-from fastapi import FastAPI
-from pydantic import BaseModel
-
-app = FastAPI()
-
-
-class Item(BaseModel):
- name: str
- price: float
- is_offer: Union[bool, None] = None
-
-
-@app.get("/")
-def read_root():
- return {"Hello": "World"}
-
-
-@app.get("/items/{item_id}")
-def read_item(item_id: int, q: Union[str, None] = None):
- return {"item_id": item_id, "q": q}
-
-
-@app.put("/items/{item_id}")
-def update_item(item_id: int, item: Item):
- return {"item_name": item.name, "item_id": item_id}
-```
-
-The `fastapi dev` server should reload automatically.
-
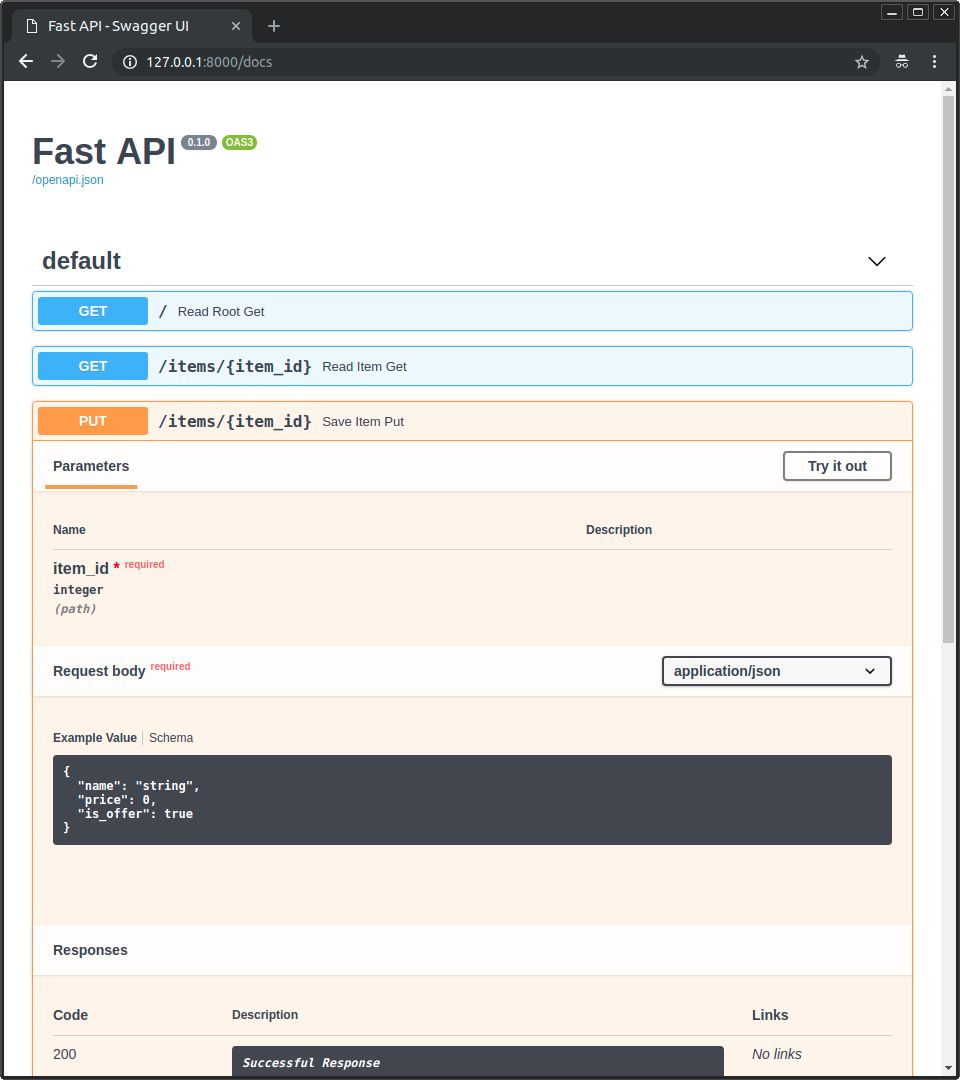
-### Interactive API docs upgrade
-
-Now go to http://127.0.0.1:8000/docs.
-
-* The interactive API documentation will be automatically updated, including the new body:
-
-
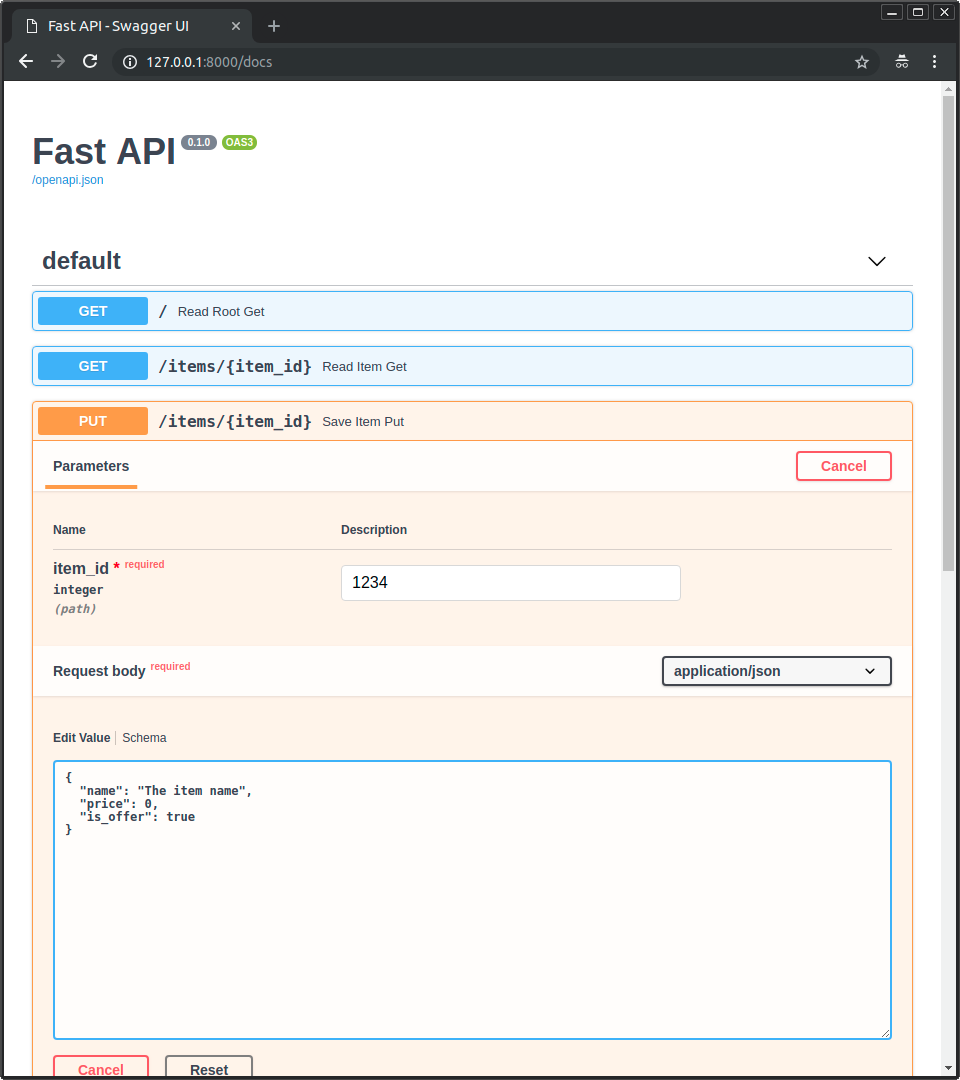
-
-* Click on the button "Try it out", it allows you to fill the parameters and directly interact with the API:
-
-
-
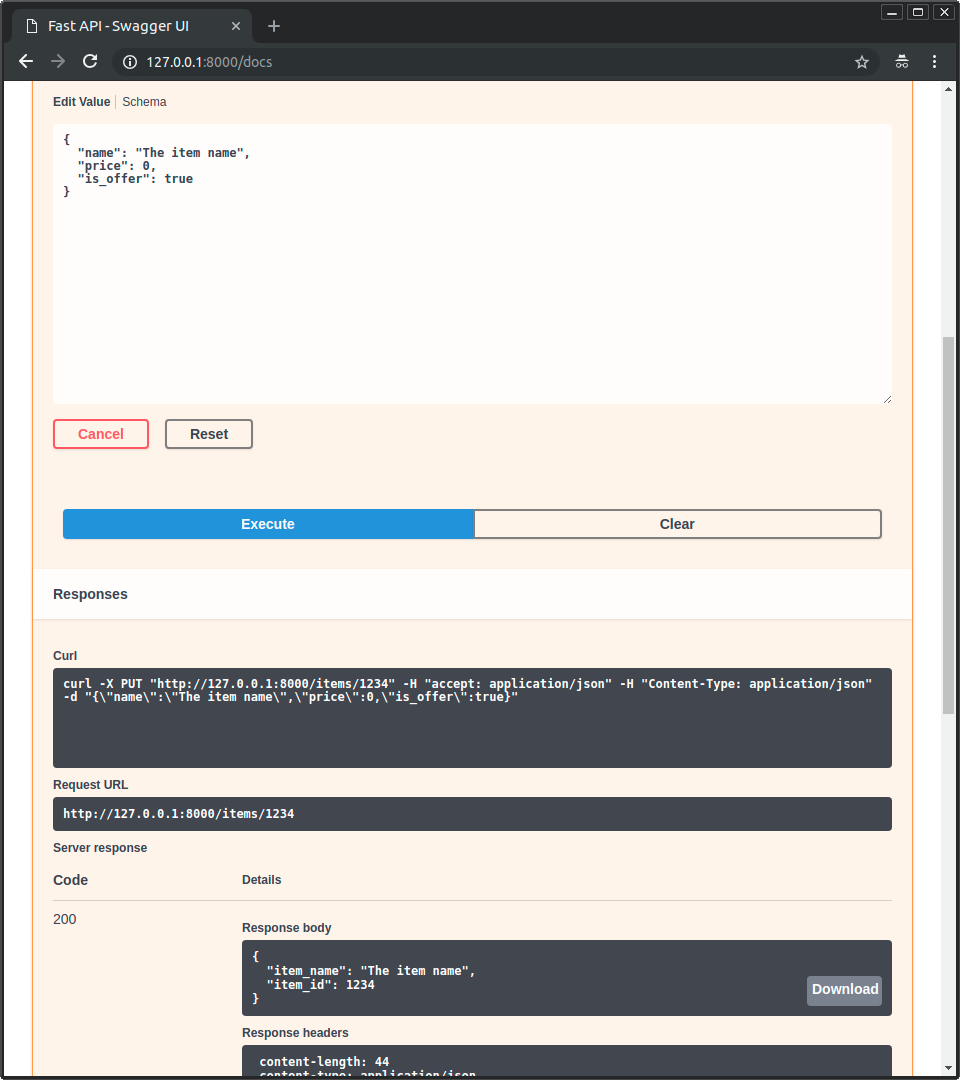
-* Then click on the "Execute" button, the user interface will communicate with your API, send the parameters, get the results and show them on the screen:
-
-
-
-### Alternative API docs upgrade
-
-And now, go to http://127.0.0.1:8000/redoc.
-
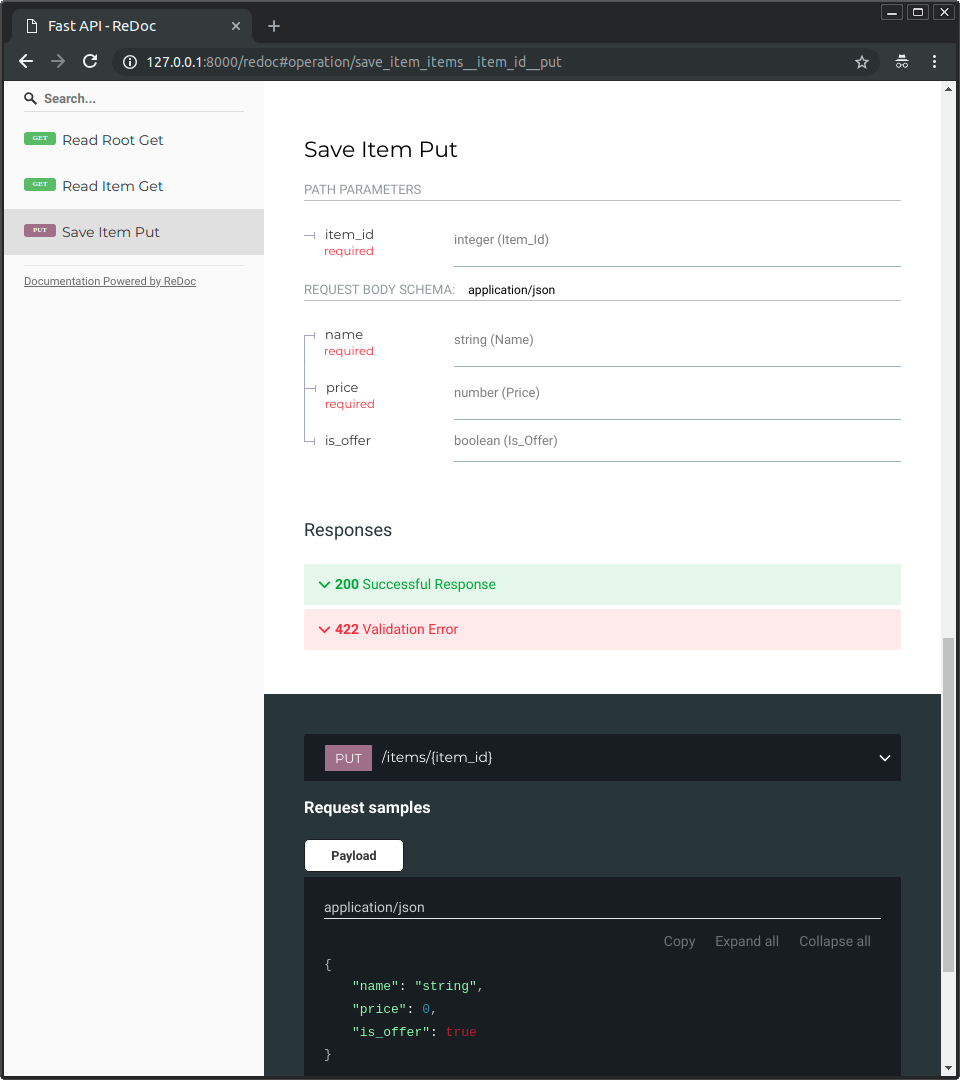
-* The alternative documentation will also reflect the new query parameter and body:
-
-
-
-### Recap
-
-In summary, you declare **once** the types of parameters, body, etc. as function parameters.
-
-You do that with standard modern Python types.
-
-You don't have to learn a new syntax, the methods or classes of a specific library, etc.
-
-Just standard **Python**.
-
-For example, for an `int`:
-
-```Python
-item_id: int
-```
-
-or for a more complex `Item` model:
-
-```Python
-item: Item
-```
-
-...and with that single declaration you get:
-
-* Editor support, including:
- * Completion.
- * Type checks.
-* Validation of data:
- * Automatic and clear errors when the data is invalid.
- * Validation even for deeply nested JSON objects.
-* Conversion of input data: coming from the network to Python data and types. Reading from:
- * JSON.
- * Path parameters.
- * Query parameters.
- * Cookies.
- * Headers.
- * Forms.
- * Files.
-* Conversion of output data: converting from Python data and types to network data (as JSON):
- * Convert Python types (`str`, `int`, `float`, `bool`, `list`, etc).
- * `datetime` objects.
- * `UUID` objects.
- * Database models.
- * ...and many more.
-* Automatic interactive API documentation, including 2 alternative user interfaces:
- * Swagger UI.
- * ReDoc.
-
----
-
-Coming back to the previous code example, **FastAPI** will:
-
-* Validate that there is an `item_id` in the path for `GET` and `PUT` requests.
-* Validate that the `item_id` is of type `int` for `GET` and `PUT` requests.
- * If it is not, the client will see a useful, clear error.
-* Check if there is an optional query parameter named `q` (as in `http://127.0.0.1:8000/items/foo?q=somequery`) for `GET` requests.
- * As the `q` parameter is declared with `= None`, it is optional.
- * Without the `None` it would be required (as is the body in the case with `PUT`).
-* For `PUT` requests to `/items/{item_id}`, read the body as JSON:
- * Check that it has a required attribute `name` that should be a `str`.
- * Check that it has a required attribute `price` that has to be a `float`.
- * Check that it has an optional attribute `is_offer`, that should be a `bool`, if present.
- * All this would also work for deeply nested JSON objects.
-* Convert from and to JSON automatically.
-* Document everything with OpenAPI, that can be used by:
- * Interactive documentation systems.
- * Automatic client code generation systems, for many languages.
-* Provide 2 interactive documentation web interfaces directly.
-
----
-
-We just scratched the surface, but you already get the idea of how it all works.
-
-Try changing the line with:
-
-```Python
- return {"item_name": item.name, "item_id": item_id}
-```
-
-...from:
-
-```Python
- ... "item_name": item.name ...
-```
-
-...to:
-
-```Python
- ... "item_price": item.price ...
-```
-
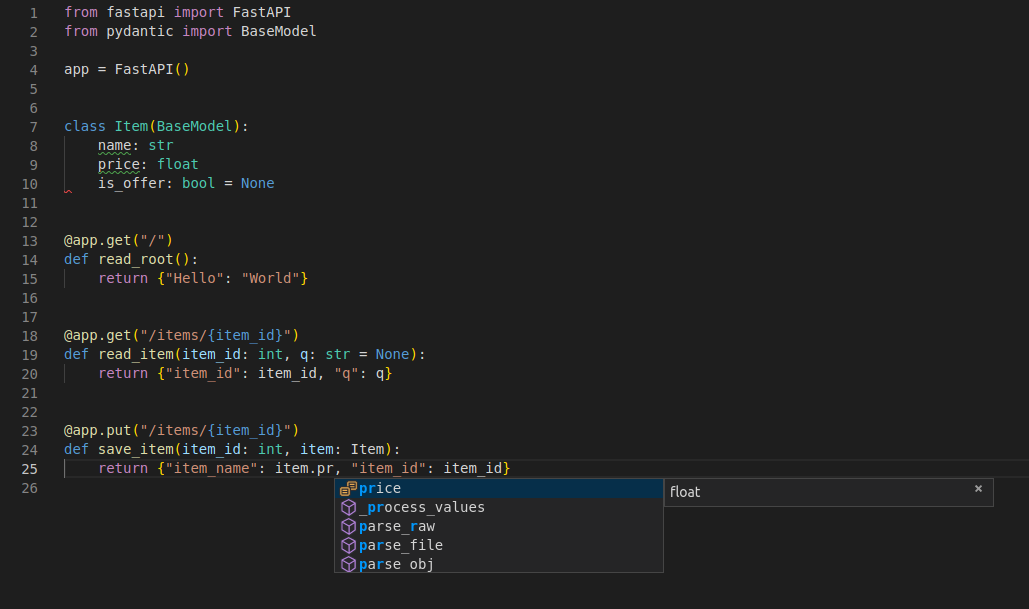
-...and see how your editor will auto-complete the attributes and know their types:
-
-
-
-For a more complete example including more features, see the Tutorial - User Guide.
-
-**Spoiler alert**: the tutorial - user guide includes:
-
-* Declaration of **parameters** from other different places as: **headers**, **cookies**, **form fields** and **files**.
-* How to set **validation constraints** as `maximum_length` or `regex`.
-* A very powerful and easy to use **Dependency Injection** system.
-* Security and authentication, including support for **OAuth2** with **JWT tokens** and **HTTP Basic** auth.
-* More advanced (but equally easy) techniques for declaring **deeply nested JSON models** (thanks to Pydantic).
-* **GraphQL** integration with Strawberry and other libraries.
-* Many extra features (thanks to Starlette) as:
- * **WebSockets**
- * extremely easy tests based on HTTPX and `pytest`
- * **CORS**
- * **Cookie Sessions**
- * ...and more.
-
-### Deploy your app (optional)
-
-You can optionally deploy your FastAPI app to FastAPI Cloud, go and join the waiting list if you haven't. 🚀
-
-If you already have a **FastAPI Cloud** account (we invited you from the waiting list 😉), you can deploy your application with one command.
-
-Before deploying, make sure you are logged in:
-
-About the command fastapi dev main.py...
-
-The command `fastapi dev` reads your `main.py` file, detects the **FastAPI** app in it, and starts a server using Uvicorn.
-
-By default, `fastapi dev` will start with auto-reload enabled for local development.
-
-You can read more about it in the FastAPI CLI docs.
-
-
-
-```console
-$ fastapi login
-
-You are logged in to FastAPI Cloud 🚀
-```
-
-
-
-Then deploy your app:
-
-
-
-```console
-$ fastapi deploy
-
-Deploying to FastAPI Cloud...
-
-✅ Deployment successful!
-
-🐔 Ready the chicken! Your app is ready at https://myapp.fastapicloud.dev
-```
-
-
-
-That's it! Now you can access your app at that URL. ✨
-
-#### About FastAPI Cloud
-
-**FastAPI Cloud** is built by the same author and team behind **FastAPI**.
-
-It streamlines the process of **building**, **deploying**, and **accessing** an API with minimal effort.
-
-It brings the same **developer experience** of building apps with FastAPI to **deploying** them to the cloud. 🎉
-
-FastAPI Cloud is the primary sponsor and funding provider for the *FastAPI and friends* open source projects. ✨
-
-#### Deploy to other cloud providers
-
-FastAPI is open source and based on standards. You can deploy FastAPI apps to any cloud provider you choose.
-
-Follow your cloud provider's guides to deploy FastAPI apps with them. 🤓
-
-## Performance
-
-Independent TechEmpower benchmarks show **FastAPI** applications running under Uvicorn as one of the fastest Python frameworks available, only below Starlette and Uvicorn themselves (used internally by FastAPI). (*)
-
-To understand more about it, see the section Benchmarks.
-
-## Dependencies
-
-FastAPI depends on Pydantic and Starlette.
-
-### `standard` Dependencies
-
-When you install FastAPI with `pip install "fastapi[standard]"` it comes with the `standard` group of optional dependencies:
-
-Used by Pydantic:
-
-* email-validator - for email validation.
-
-Used by Starlette:
-
-* httpx - Required if you want to use the `TestClient`.
-* jinja2 - Required if you want to use the default template configuration.
-* python-multipart - Required if you want to support form "parsing", with `request.form()`.
-
-Used by FastAPI:
-
-* uvicorn - for the server that loads and serves your application. This includes `uvicorn[standard]`, which includes some dependencies (e.g. `uvloop`) needed for high performance serving.
-* `fastapi-cli[standard]` - to provide the `fastapi` command.
- * This includes `fastapi-cloud-cli`, which allows you to deploy your FastAPI application to FastAPI Cloud.
-
-### Without `standard` Dependencies
-
-If you don't want to include the `standard` optional dependencies, you can install with `pip install fastapi` instead of `pip install "fastapi[standard]"`.
-
-### Without `fastapi-cloud-cli`
-
-If you want to install FastAPI with the standard dependencies but without the `fastapi-cloud-cli`, you can install with `pip install "fastapi[standard-no-fastapi-cloud-cli]"`.
-
-### Additional Optional Dependencies
-
-There are some additional dependencies you might want to install.
-
-Additional optional Pydantic dependencies:
-
-* pydantic-settings - for settings management.
-* pydantic-extra-types - for extra types to be used with Pydantic.
-
-Additional optional FastAPI dependencies:
-
-* orjson - Required if you want to use `ORJSONResponse`.
-* ujson - Required if you want to use `UJSONResponse`.
-
-## License
-
-This project is licensed under the terms of the MIT license.
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/RECORD b/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/RECORD
deleted file mode 100644
index 372e3e4..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/RECORD
+++ /dev/null
@@ -1,103 +0,0 @@
-../../../bin/fastapi,sha256=YoJmb9ZCq_mki6xo8vzXXMZGMucbJZsUkvK0Sh_J-KE,213
-fastapi-0.128.0.dist-info/INSTALLER,sha256=zuuue4knoyJ-UwPPXg8fezS7VCrXJQrAP7zeNuwvFQg,4
-fastapi-0.128.0.dist-info/METADATA,sha256=hKL7LtKoBl4ojHSJ_u5MsihJRMPBU5AsppXt75m24FY,30977
-fastapi-0.128.0.dist-info/RECORD,,
-fastapi-0.128.0.dist-info/REQUESTED,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
-fastapi-0.128.0.dist-info/WHEEL,sha256=tsUv_t7BDeJeRHaSrczbGeuK-TtDpGsWi_JfpzD255I,90
-fastapi-0.128.0.dist-info/entry_points.txt,sha256=GCf-WbIZxyGT4MUmrPGj1cOHYZoGsNPHAvNkT6hnGeA,61
-fastapi-0.128.0.dist-info/licenses/LICENSE,sha256=Tsif_IFIW5f-xYSy1KlhAy7v_oNEU4lP2cEnSQbMdE4,1086
-fastapi/__init__.py,sha256=wlYVfo3p5m4F8JxyVpV1aFS5XKRzgCXBfB9s231GveY,1081
-fastapi/__main__.py,sha256=bKePXLdO4SsVSM6r9SVoLickJDcR2c0cTOxZRKq26YQ,37
-fastapi/__pycache__/__init__.cpython-312.pyc,,
-fastapi/__pycache__/__main__.cpython-312.pyc,,
-fastapi/__pycache__/applications.cpython-312.pyc,,
-fastapi/__pycache__/background.cpython-312.pyc,,
-fastapi/__pycache__/cli.cpython-312.pyc,,
-fastapi/__pycache__/concurrency.cpython-312.pyc,,
-fastapi/__pycache__/datastructures.cpython-312.pyc,,
-fastapi/__pycache__/encoders.cpython-312.pyc,,
-fastapi/__pycache__/exception_handlers.cpython-312.pyc,,
-fastapi/__pycache__/exceptions.cpython-312.pyc,,
-fastapi/__pycache__/logger.cpython-312.pyc,,
-fastapi/__pycache__/param_functions.cpython-312.pyc,,
-fastapi/__pycache__/params.cpython-312.pyc,,
-fastapi/__pycache__/requests.cpython-312.pyc,,
-fastapi/__pycache__/responses.cpython-312.pyc,,
-fastapi/__pycache__/routing.cpython-312.pyc,,
-fastapi/__pycache__/staticfiles.cpython-312.pyc,,
-fastapi/__pycache__/templating.cpython-312.pyc,,
-fastapi/__pycache__/testclient.cpython-312.pyc,,
-fastapi/__pycache__/types.cpython-312.pyc,,
-fastapi/__pycache__/utils.cpython-312.pyc,,
-fastapi/__pycache__/websockets.cpython-312.pyc,,
-fastapi/_compat/__init__.py,sha256=o3dg67W5LlwA52_1Y9Re_JhelcG0oj5ke_GdQHcwBnw,2226
-fastapi/_compat/__pycache__/__init__.cpython-312.pyc,,
-fastapi/_compat/__pycache__/shared.cpython-312.pyc,,
-fastapi/_compat/__pycache__/v2.cpython-312.pyc,,
-fastapi/_compat/shared.py,sha256=yFZWOnzG1JRIPuLOk0eaBcrwP2bap8UkP5I0XBuVZck,6842
-fastapi/_compat/v2.py,sha256=B5OawqkcpTaaDLNZDHFlasGQyYFS7VFbwyDVwUTydE0,19597
-fastapi/applications.py,sha256=IO5F5FdRacBFXYxGPk7zPbwRCa-cxN74HHf0eMEp7xE,180536
-fastapi/background.py,sha256=fDNVXWBZniIQIxW3v-Sc99FT2p4RDKOOWW2fhOe4Nko,1793
-fastapi/cli.py,sha256=OYhZb0NR_deuT5ofyPF2NoNBzZDNOP8Salef2nk-HqA,418
-fastapi/concurrency.py,sha256=xHGDEOQAA6cvFEDX46oq3r2t1Zd4sVvreaRgdIE4juM,1489
-fastapi/datastructures.py,sha256=41qs2ZhTzORMGn7JSAF9qsiPY9XP4uGyGOMKhfzg4i4,5205
-fastapi/dependencies/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
-fastapi/dependencies/__pycache__/__init__.cpython-312.pyc,,
-fastapi/dependencies/__pycache__/models.cpython-312.pyc,,
-fastapi/dependencies/__pycache__/utils.cpython-312.pyc,,
-fastapi/dependencies/models.py,sha256=TjJB2l6m-vhFkau7ysLdgcymZ6SdIJmlrJjqMJs5TZc,7317
-fastapi/dependencies/utils.py,sha256=rJQFCFUC7q765yUcOoSV78GCyTGfS2ePLbMvJ2B-yLc,38549
-fastapi/encoders.py,sha256=uQfXjliV2O93wy7sng3pUuLZw9UOw8HNsAHb2B1ZfEs,11004
-fastapi/exception_handlers.py,sha256=YVcT8Zy021VYYeecgdyh5YEUjEIHKcLspbkSf4OfbJI,1275
-fastapi/exceptions.py,sha256=enNT5h_wDyzY90qA4a_VqMDRSUNHTd1LX_vihMNa-LE,6973
-fastapi/logger.py,sha256=I9NNi3ov8AcqbsbC9wl1X-hdItKgYt2XTrx1f99Zpl4,54
-fastapi/middleware/__init__.py,sha256=oQDxiFVcc1fYJUOIFvphnK7pTT5kktmfL32QXpBFvvo,58
-fastapi/middleware/__pycache__/__init__.cpython-312.pyc,,
-fastapi/middleware/__pycache__/asyncexitstack.cpython-312.pyc,,
-fastapi/middleware/__pycache__/cors.cpython-312.pyc,,
-fastapi/middleware/__pycache__/gzip.cpython-312.pyc,,
-fastapi/middleware/__pycache__/httpsredirect.cpython-312.pyc,,
-fastapi/middleware/__pycache__/trustedhost.cpython-312.pyc,,
-fastapi/middleware/__pycache__/wsgi.cpython-312.pyc,,
-fastapi/middleware/asyncexitstack.py,sha256=RKGlQpGzg3GLosqVhrxBy_NCZ9qJS7zQeNHt5Y3x-00,637
-fastapi/middleware/cors.py,sha256=ynwjWQZoc_vbhzZ3_ZXceoaSrslHFHPdoM52rXr0WUU,79
-fastapi/middleware/gzip.py,sha256=xM5PcsH8QlAimZw4VDvcmTnqQamslThsfe3CVN2voa0,79
-fastapi/middleware/httpsredirect.py,sha256=rL8eXMnmLijwVkH7_400zHri1AekfeBd6D6qs8ix950,115
-fastapi/middleware/trustedhost.py,sha256=eE5XGRxGa7c5zPnMJDGp3BxaL25k5iVQlhnv-Pk0Pss,109
-fastapi/middleware/wsgi.py,sha256=Z3Ue-7wni4lUZMvH3G9ek__acgYdJstbnpZX_HQAboY,79
-fastapi/openapi/__init__.py,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
-fastapi/openapi/__pycache__/__init__.cpython-312.pyc,,
-fastapi/openapi/__pycache__/constants.cpython-312.pyc,,
-fastapi/openapi/__pycache__/docs.cpython-312.pyc,,
-fastapi/openapi/__pycache__/models.cpython-312.pyc,,
-fastapi/openapi/__pycache__/utils.cpython-312.pyc,,
-fastapi/openapi/constants.py,sha256=adGzmis1L1HJRTE3kJ5fmHS_Noq6tIY6pWv_SFzoFDU,153
-fastapi/openapi/docs.py,sha256=wqcXZOhBdnf2pilVNyAIfjKAhfH9MXaQiitwZeJCR7I,10335
-fastapi/openapi/models.py,sha256=xJfPRE7DqNvtqgdouXbtMCCLBrZ-4Bd87QaA_WPUVTA,15419
-fastapi/openapi/utils.py,sha256=HsOqZ8uWSTUYL18jhYI0gU-A1nLHCNu3k3UEIAVzRyY,23795
-fastapi/param_functions.py,sha256=O8bsr2xM8XODE0wjtev8sZLl3Tt_glpdQteM2relVrU,64466
-fastapi/params.py,sha256=YS7z57t0N4H8Rdogx1sU6R-KZDcLn5y46SGz8z5lX-s,26982
-fastapi/py.typed,sha256=47DEQpj8HBSa-_TImW-5JCeuQeRkm5NMpJWZG3hSuFU,0
-fastapi/requests.py,sha256=zayepKFcienBllv3snmWI20Gk0oHNVLU4DDhqXBb4LU,142
-fastapi/responses.py,sha256=QNQQlwpKhQoIPZTTWkpc9d_QGeGZ_aVQPaDV3nQ8m7c,1761
-fastapi/routing.py,sha256=dHZW6NLzbvD7jZT2N-V6fj1Irbe8HR-FDeiBNSuTHHs,178746
-fastapi/security/__init__.py,sha256=bO8pNmxqVRXUjfl2mOKiVZLn0FpBQ61VUYVjmppnbJw,881
-fastapi/security/__pycache__/__init__.cpython-312.pyc,,
-fastapi/security/__pycache__/api_key.cpython-312.pyc,,
-fastapi/security/__pycache__/base.cpython-312.pyc,,
-fastapi/security/__pycache__/http.cpython-312.pyc,,
-fastapi/security/__pycache__/oauth2.cpython-312.pyc,,
-fastapi/security/__pycache__/open_id_connect_url.cpython-312.pyc,,
-fastapi/security/__pycache__/utils.cpython-312.pyc,,
-fastapi/security/api_key.py,sha256=5AriUhrA_KgdtJRJ_BtCDgcTFOUlUUvDSultdIfdApc,9799
-fastapi/security/base.py,sha256=dl4pvbC-RxjfbWgPtCWd8MVU-7CB2SZ22rJDXVCXO6c,141
-fastapi/security/http.py,sha256=gckOhSa1ubLpARU819pxKiZZnmnyg_co6AwQyNE8yxw,13518
-fastapi/security/oauth2.py,sha256=8sU0yRncO_1mK8rdUES1GRijPawi2ZGwLGWphWeS02w,22477
-fastapi/security/open_id_connect_url.py,sha256=pFvSVESThhjYXSDWPlFGtm9bN62JXHzuwnVfmtyNcZE,3158
-fastapi/security/utils.py,sha256=Gk6KGztJnYqvYFTmuQO7ow_icayiqP3HL762ZFRQjfU,286
-fastapi/staticfiles.py,sha256=iirGIt3sdY2QZXd36ijs3Cj-T0FuGFda3cd90kM9Ikw,69
-fastapi/templating.py,sha256=4zsuTWgcjcEainMJFAlW6-gnslm6AgOS1SiiDWfmQxk,76
-fastapi/testclient.py,sha256=nBvaAmX66YldReJNZXPOk1sfuo2Q6hs8bOvIaCep6LQ,66
-fastapi/types.py,sha256=W0HOmfeZw_3PcMDOa6GA-Or9okP9hf_260UkbCfKHY4,455
-fastapi/utils.py,sha256=sl-ddHjWbQiLUNLFiG93IXStAZgp8NSFwJsjo41mb04,5230
-fastapi/websockets.py,sha256=419uncYObEKZG0YcrXscfQQYLSWoE10jqxVMetGdR98,222
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/REQUESTED b/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/REQUESTED
deleted file mode 100644
index e69de29..0000000
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/WHEEL b/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/WHEEL
deleted file mode 100644
index 2efd4ed..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/WHEEL
+++ /dev/null
@@ -1,4 +0,0 @@
-Wheel-Version: 1.0
-Generator: pdm-backend (2.4.6)
-Root-Is-Purelib: true
-Tag: py3-none-any
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/entry_points.txt b/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/entry_points.txt
deleted file mode 100644
index b81849e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/entry_points.txt
+++ /dev/null
@@ -1,5 +0,0 @@
-[console_scripts]
-fastapi = fastapi.cli:main
-
-[gui_scripts]
-
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/licenses/LICENSE b/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/licenses/LICENSE
deleted file mode 100644
index 3e92463..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi-0.128.0.dist-info/licenses/LICENSE
+++ /dev/null
@@ -1,21 +0,0 @@
-The MIT License (MIT)
-
-Copyright (c) 2018 Sebastián Ramírez
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in
-all copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
-THE SOFTWARE.
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__init__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/__init__.py
deleted file mode 100644
index 6133787..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/__init__.py
+++ /dev/null
@@ -1,25 +0,0 @@
-"""FastAPI framework, high performance, easy to learn, fast to code, ready for production"""
-
-__version__ = "0.128.0"
-
-from starlette import status as status
-
-from .applications import FastAPI as FastAPI
-from .background import BackgroundTasks as BackgroundTasks
-from .datastructures import UploadFile as UploadFile
-from .exceptions import HTTPException as HTTPException
-from .exceptions import WebSocketException as WebSocketException
-from .param_functions import Body as Body
-from .param_functions import Cookie as Cookie
-from .param_functions import Depends as Depends
-from .param_functions import File as File
-from .param_functions import Form as Form
-from .param_functions import Header as Header
-from .param_functions import Path as Path
-from .param_functions import Query as Query
-from .param_functions import Security as Security
-from .requests import Request as Request
-from .responses import Response as Response
-from .routing import APIRouter as APIRouter
-from .websockets import WebSocket as WebSocket
-from .websockets import WebSocketDisconnect as WebSocketDisconnect
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__main__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/__main__.py
deleted file mode 100644
index fc36465..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/__main__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from fastapi.cli import main
-
-main()
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index 8321df2..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__main__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__main__.cpython-312.pyc
deleted file mode 100644
index 3ae7c07..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/__main__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/applications.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/applications.cpython-312.pyc
deleted file mode 100644
index d2664be..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/applications.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/background.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/background.cpython-312.pyc
deleted file mode 100644
index e0081cf..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/background.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/cli.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/cli.cpython-312.pyc
deleted file mode 100644
index 4a99f9f..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/cli.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/concurrency.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/concurrency.cpython-312.pyc
deleted file mode 100644
index fa3f4da..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/concurrency.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/datastructures.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/datastructures.cpython-312.pyc
deleted file mode 100644
index 4b89595..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/datastructures.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/encoders.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/encoders.cpython-312.pyc
deleted file mode 100644
index 9d02f78..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/encoders.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exception_handlers.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exception_handlers.cpython-312.pyc
deleted file mode 100644
index 0d7ab64..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exception_handlers.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exceptions.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exceptions.cpython-312.pyc
deleted file mode 100644
index ebd0482..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/exceptions.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/logger.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/logger.cpython-312.pyc
deleted file mode 100644
index 175467f..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/logger.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/param_functions.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/param_functions.cpython-312.pyc
deleted file mode 100644
index e1dd42f..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/param_functions.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/params.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/params.cpython-312.pyc
deleted file mode 100644
index 744780c..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/params.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/requests.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/requests.cpython-312.pyc
deleted file mode 100644
index a5f016d..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/requests.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/responses.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/responses.cpython-312.pyc
deleted file mode 100644
index e4db996..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/responses.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/routing.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/routing.cpython-312.pyc
deleted file mode 100644
index af52ea5..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/routing.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/staticfiles.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/staticfiles.cpython-312.pyc
deleted file mode 100644
index bad5945..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/staticfiles.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/templating.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/templating.cpython-312.pyc
deleted file mode 100644
index c3dbeb0..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/templating.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/testclient.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/testclient.cpython-312.pyc
deleted file mode 100644
index 36c23cf..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/testclient.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/types.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/types.cpython-312.pyc
deleted file mode 100644
index 88878ab..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/types.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/utils.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/utils.cpython-312.pyc
deleted file mode 100644
index 06a0c9d..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/utils.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/websockets.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/websockets.cpython-312.pyc
deleted file mode 100644
index d3544ea..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/__pycache__/websockets.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__init__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__init__.py
deleted file mode 100644
index 3dfaf9b..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__init__.py
+++ /dev/null
@@ -1,41 +0,0 @@
-from .shared import PYDANTIC_V2 as PYDANTIC_V2
-from .shared import PYDANTIC_VERSION_MINOR_TUPLE as PYDANTIC_VERSION_MINOR_TUPLE
-from .shared import annotation_is_pydantic_v1 as annotation_is_pydantic_v1
-from .shared import field_annotation_is_scalar as field_annotation_is_scalar
-from .shared import is_pydantic_v1_model_class as is_pydantic_v1_model_class
-from .shared import is_pydantic_v1_model_instance as is_pydantic_v1_model_instance
-from .shared import (
- is_uploadfile_or_nonable_uploadfile_annotation as is_uploadfile_or_nonable_uploadfile_annotation,
-)
-from .shared import (
- is_uploadfile_sequence_annotation as is_uploadfile_sequence_annotation,
-)
-from .shared import lenient_issubclass as lenient_issubclass
-from .shared import sequence_types as sequence_types
-from .shared import value_is_sequence as value_is_sequence
-from .v2 import BaseConfig as BaseConfig
-from .v2 import ModelField as ModelField
-from .v2 import PydanticSchemaGenerationError as PydanticSchemaGenerationError
-from .v2 import RequiredParam as RequiredParam
-from .v2 import Undefined as Undefined
-from .v2 import UndefinedType as UndefinedType
-from .v2 import Url as Url
-from .v2 import Validator as Validator
-from .v2 import _regenerate_error_with_loc as _regenerate_error_with_loc
-from .v2 import copy_field_info as copy_field_info
-from .v2 import create_body_model as create_body_model
-from .v2 import evaluate_forwardref as evaluate_forwardref
-from .v2 import get_cached_model_fields as get_cached_model_fields
-from .v2 import get_compat_model_name_map as get_compat_model_name_map
-from .v2 import get_definitions as get_definitions
-from .v2 import get_missing_field_error as get_missing_field_error
-from .v2 import get_schema_from_model_field as get_schema_from_model_field
-from .v2 import is_bytes_field as is_bytes_field
-from .v2 import is_bytes_sequence_field as is_bytes_sequence_field
-from .v2 import is_scalar_field as is_scalar_field
-from .v2 import is_scalar_sequence_field as is_scalar_sequence_field
-from .v2 import is_sequence_field as is_sequence_field
-from .v2 import serialize_sequence_value as serialize_sequence_value
-from .v2 import (
- with_info_plain_validator_function as with_info_plain_validator_function,
-)
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index c7137c3..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/shared.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/shared.cpython-312.pyc
deleted file mode 100644
index 6b9fac3..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/shared.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/v2.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/v2.cpython-312.pyc
deleted file mode 100644
index 638586c..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/__pycache__/v2.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/shared.py b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/shared.py
deleted file mode 100644
index 419b58f..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/shared.py
+++ /dev/null
@@ -1,206 +0,0 @@
-import sys
-import types
-import typing
-import warnings
-from collections import deque
-from collections.abc import Mapping, Sequence
-from dataclasses import is_dataclass
-from typing import (
- Annotated,
- Any,
- Union,
-)
-
-from fastapi.types import UnionType
-from pydantic import BaseModel
-from pydantic.version import VERSION as PYDANTIC_VERSION
-from starlette.datastructures import UploadFile
-from typing_extensions import get_args, get_origin
-
-# Copy from Pydantic v2, compatible with v1
-if sys.version_info < (3, 10):
- WithArgsTypes: tuple[Any, ...] = (typing._GenericAlias, types.GenericAlias) # type: ignore[attr-defined]
-else:
- WithArgsTypes: tuple[Any, ...] = (
- typing._GenericAlias, # type: ignore[attr-defined]
- types.GenericAlias,
- types.UnionType,
- ) # pyright: ignore[reportAttributeAccessIssue]
-
-PYDANTIC_VERSION_MINOR_TUPLE = tuple(int(x) for x in PYDANTIC_VERSION.split(".")[:2])
-PYDANTIC_V2 = PYDANTIC_VERSION_MINOR_TUPLE[0] == 2
-
-
-sequence_annotation_to_type = {
- Sequence: list,
- list: list,
- tuple: tuple,
- set: set,
- frozenset: frozenset,
- deque: deque,
-}
-
-sequence_types = tuple(sequence_annotation_to_type.keys())
-
-Url: type[Any]
-
-
-# Copy of Pydantic v2, compatible with v1
-def lenient_issubclass(
- cls: Any, class_or_tuple: Union[type[Any], tuple[type[Any], ...], None]
-) -> bool:
- try:
- return isinstance(cls, type) and issubclass(cls, class_or_tuple) # type: ignore[arg-type]
- except TypeError: # pragma: no cover
- if isinstance(cls, WithArgsTypes):
- return False
- raise # pragma: no cover
-
-
-def _annotation_is_sequence(annotation: Union[type[Any], None]) -> bool:
- if lenient_issubclass(annotation, (str, bytes)):
- return False
- return lenient_issubclass(annotation, sequence_types)
-
-
-def field_annotation_is_sequence(annotation: Union[type[Any], None]) -> bool:
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- for arg in get_args(annotation):
- if field_annotation_is_sequence(arg):
- return True
- return False
- return _annotation_is_sequence(annotation) or _annotation_is_sequence(
- get_origin(annotation)
- )
-
-
-def value_is_sequence(value: Any) -> bool:
- return isinstance(value, sequence_types) and not isinstance(value, (str, bytes))
-
-
-def _annotation_is_complex(annotation: Union[type[Any], None]) -> bool:
- return (
- lenient_issubclass(annotation, (BaseModel, Mapping, UploadFile))
- or _annotation_is_sequence(annotation)
- or is_dataclass(annotation)
- )
-
-
-def field_annotation_is_complex(annotation: Union[type[Any], None]) -> bool:
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- return any(field_annotation_is_complex(arg) for arg in get_args(annotation))
-
- if origin is Annotated:
- return field_annotation_is_complex(get_args(annotation)[0])
-
- return (
- _annotation_is_complex(annotation)
- or _annotation_is_complex(origin)
- or hasattr(origin, "__pydantic_core_schema__")
- or hasattr(origin, "__get_pydantic_core_schema__")
- )
-
-
-def field_annotation_is_scalar(annotation: Any) -> bool:
- # handle Ellipsis here to make tuple[int, ...] work nicely
- return annotation is Ellipsis or not field_annotation_is_complex(annotation)
-
-
-def field_annotation_is_scalar_sequence(annotation: Union[type[Any], None]) -> bool:
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- at_least_one_scalar_sequence = False
- for arg in get_args(annotation):
- if field_annotation_is_scalar_sequence(arg):
- at_least_one_scalar_sequence = True
- continue
- elif not field_annotation_is_scalar(arg):
- return False
- return at_least_one_scalar_sequence
- return field_annotation_is_sequence(annotation) and all(
- field_annotation_is_scalar(sub_annotation)
- for sub_annotation in get_args(annotation)
- )
-
-
-def is_bytes_or_nonable_bytes_annotation(annotation: Any) -> bool:
- if lenient_issubclass(annotation, bytes):
- return True
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- for arg in get_args(annotation):
- if lenient_issubclass(arg, bytes):
- return True
- return False
-
-
-def is_uploadfile_or_nonable_uploadfile_annotation(annotation: Any) -> bool:
- if lenient_issubclass(annotation, UploadFile):
- return True
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- for arg in get_args(annotation):
- if lenient_issubclass(arg, UploadFile):
- return True
- return False
-
-
-def is_bytes_sequence_annotation(annotation: Any) -> bool:
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- at_least_one = False
- for arg in get_args(annotation):
- if is_bytes_sequence_annotation(arg):
- at_least_one = True
- continue
- return at_least_one
- return field_annotation_is_sequence(annotation) and all(
- is_bytes_or_nonable_bytes_annotation(sub_annotation)
- for sub_annotation in get_args(annotation)
- )
-
-
-def is_uploadfile_sequence_annotation(annotation: Any) -> bool:
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- at_least_one = False
- for arg in get_args(annotation):
- if is_uploadfile_sequence_annotation(arg):
- at_least_one = True
- continue
- return at_least_one
- return field_annotation_is_sequence(annotation) and all(
- is_uploadfile_or_nonable_uploadfile_annotation(sub_annotation)
- for sub_annotation in get_args(annotation)
- )
-
-
-def is_pydantic_v1_model_instance(obj: Any) -> bool:
- with warnings.catch_warnings():
- warnings.simplefilter("ignore", UserWarning)
- from pydantic import v1
- return isinstance(obj, v1.BaseModel)
-
-
-def is_pydantic_v1_model_class(cls: Any) -> bool:
- with warnings.catch_warnings():
- warnings.simplefilter("ignore", UserWarning)
- from pydantic import v1
- return lenient_issubclass(cls, v1.BaseModel)
-
-
-def annotation_is_pydantic_v1(annotation: Any) -> bool:
- if is_pydantic_v1_model_class(annotation):
- return True
- origin = get_origin(annotation)
- if origin is Union or origin is UnionType:
- for arg in get_args(annotation):
- if is_pydantic_v1_model_class(arg):
- return True
- if field_annotation_is_sequence(annotation):
- for sub_annotation in get_args(annotation):
- if annotation_is_pydantic_v1(sub_annotation):
- return True
- return False
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/v2.py b/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/v2.py
deleted file mode 100644
index 25b6814..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/_compat/v2.py
+++ /dev/null
@@ -1,568 +0,0 @@
-import re
-import warnings
-from collections.abc import Sequence
-from copy import copy, deepcopy
-from dataclasses import dataclass, is_dataclass
-from enum import Enum
-from functools import lru_cache
-from typing import (
- Annotated,
- Any,
- Union,
- cast,
-)
-
-from fastapi._compat import shared
-from fastapi.openapi.constants import REF_TEMPLATE
-from fastapi.types import IncEx, ModelNameMap, UnionType
-from pydantic import BaseModel, ConfigDict, Field, TypeAdapter, create_model
-from pydantic import PydanticSchemaGenerationError as PydanticSchemaGenerationError
-from pydantic import PydanticUndefinedAnnotation as PydanticUndefinedAnnotation
-from pydantic import ValidationError as ValidationError
-from pydantic._internal._schema_generation_shared import ( # type: ignore[attr-defined]
- GetJsonSchemaHandler as GetJsonSchemaHandler,
-)
-from pydantic._internal._typing_extra import eval_type_lenient
-from pydantic._internal._utils import lenient_issubclass as lenient_issubclass
-from pydantic.fields import FieldInfo as FieldInfo
-from pydantic.json_schema import GenerateJsonSchema as GenerateJsonSchema
-from pydantic.json_schema import JsonSchemaValue as JsonSchemaValue
-from pydantic_core import CoreSchema as CoreSchema
-from pydantic_core import PydanticUndefined, PydanticUndefinedType
-from pydantic_core import Url as Url
-from typing_extensions import Literal, get_args, get_origin
-
-try:
- from pydantic_core.core_schema import (
- with_info_plain_validator_function as with_info_plain_validator_function,
- )
-except ImportError: # pragma: no cover
- from pydantic_core.core_schema import (
- general_plain_validator_function as with_info_plain_validator_function, # noqa: F401
- )
-
-RequiredParam = PydanticUndefined
-Undefined = PydanticUndefined
-UndefinedType = PydanticUndefinedType
-evaluate_forwardref = eval_type_lenient
-Validator = Any
-
-# TODO: remove when dropping support for Pydantic < v2.12.3
-_Attrs = {
- "default": ...,
- "default_factory": None,
- "alias": None,
- "alias_priority": None,
- "validation_alias": None,
- "serialization_alias": None,
- "title": None,
- "field_title_generator": None,
- "description": None,
- "examples": None,
- "exclude": None,
- "exclude_if": None,
- "discriminator": None,
- "deprecated": None,
- "json_schema_extra": None,
- "frozen": None,
- "validate_default": None,
- "repr": True,
- "init": None,
- "init_var": None,
- "kw_only": None,
-}
-
-
-# TODO: remove when dropping support for Pydantic < v2.12.3
-def asdict(field_info: FieldInfo) -> dict[str, Any]:
- attributes = {}
- for attr in _Attrs:
- value = getattr(field_info, attr, Undefined)
- if value is not Undefined:
- attributes[attr] = value
- return {
- "annotation": field_info.annotation,
- "metadata": field_info.metadata,
- "attributes": attributes,
- }
-
-
-class BaseConfig:
- pass
-
-
-class ErrorWrapper(Exception):
- pass
-
-
-@dataclass
-class ModelField:
- field_info: FieldInfo
- name: str
- mode: Literal["validation", "serialization"] = "validation"
- config: Union[ConfigDict, None] = None
-
- @property
- def alias(self) -> str:
- a = self.field_info.alias
- return a if a is not None else self.name
-
- @property
- def validation_alias(self) -> Union[str, None]:
- va = self.field_info.validation_alias
- if isinstance(va, str) and va:
- return va
- return None
-
- @property
- def serialization_alias(self) -> Union[str, None]:
- sa = self.field_info.serialization_alias
- return sa or None
-
- @property
- def required(self) -> bool:
- return self.field_info.is_required()
-
- @property
- def default(self) -> Any:
- return self.get_default()
-
- @property
- def type_(self) -> Any:
- return self.field_info.annotation
-
- def __post_init__(self) -> None:
- with warnings.catch_warnings():
- # Pydantic >= 2.12.0 warns about field specific metadata that is unused
- # (e.g. `TypeAdapter(Annotated[int, Field(alias='b')])`). In some cases, we
- # end up building the type adapter from a model field annotation so we
- # need to ignore the warning:
- if shared.PYDANTIC_VERSION_MINOR_TUPLE >= (2, 12):
- from pydantic.warnings import UnsupportedFieldAttributeWarning
-
- warnings.simplefilter(
- "ignore", category=UnsupportedFieldAttributeWarning
- )
- # TODO: remove after dropping support for Python 3.8 and
- # setting the min Pydantic to v2.12.3 that adds asdict()
- field_dict = asdict(self.field_info)
- annotated_args = (
- field_dict["annotation"],
- *field_dict["metadata"],
- # this FieldInfo needs to be created again so that it doesn't include
- # the old field info metadata and only the rest of the attributes
- Field(**field_dict["attributes"]),
- )
- self._type_adapter: TypeAdapter[Any] = TypeAdapter(
- Annotated[annotated_args],
- config=self.config,
- )
-
- def get_default(self) -> Any:
- if self.field_info.is_required():
- return Undefined
- return self.field_info.get_default(call_default_factory=True)
-
- def validate(
- self,
- value: Any,
- values: dict[str, Any] = {}, # noqa: B006
- *,
- loc: tuple[Union[int, str], ...] = (),
- ) -> tuple[Any, Union[list[dict[str, Any]], None]]:
- try:
- return (
- self._type_adapter.validate_python(value, from_attributes=True),
- None,
- )
- except ValidationError as exc:
- return None, _regenerate_error_with_loc(
- errors=exc.errors(include_url=False), loc_prefix=loc
- )
-
- def serialize(
- self,
- value: Any,
- *,
- mode: Literal["json", "python"] = "json",
- include: Union[IncEx, None] = None,
- exclude: Union[IncEx, None] = None,
- by_alias: bool = True,
- exclude_unset: bool = False,
- exclude_defaults: bool = False,
- exclude_none: bool = False,
- ) -> Any:
- # What calls this code passes a value that already called
- # self._type_adapter.validate_python(value)
- return self._type_adapter.dump_python(
- value,
- mode=mode,
- include=include,
- exclude=exclude,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_defaults=exclude_defaults,
- exclude_none=exclude_none,
- )
-
- def __hash__(self) -> int:
- # Each ModelField is unique for our purposes, to allow making a dict from
- # ModelField to its JSON Schema.
- return id(self)
-
-
-def _has_computed_fields(field: ModelField) -> bool:
- computed_fields = field._type_adapter.core_schema.get("schema", {}).get(
- "computed_fields", []
- )
- return len(computed_fields) > 0
-
-
-def get_schema_from_model_field(
- *,
- field: ModelField,
- model_name_map: ModelNameMap,
- field_mapping: dict[
- tuple[ModelField, Literal["validation", "serialization"]], JsonSchemaValue
- ],
- separate_input_output_schemas: bool = True,
-) -> dict[str, Any]:
- override_mode: Union[Literal["validation"], None] = (
- None
- if (separate_input_output_schemas or _has_computed_fields(field))
- else "validation"
- )
- field_alias = (
- (field.validation_alias or field.alias)
- if field.mode == "validation"
- else (field.serialization_alias or field.alias)
- )
-
- # This expects that GenerateJsonSchema was already used to generate the definitions
- json_schema = field_mapping[(field, override_mode or field.mode)]
- if "$ref" not in json_schema:
- # TODO remove when deprecating Pydantic v1
- # Ref: https://github.com/pydantic/pydantic/blob/d61792cc42c80b13b23e3ffa74bc37ec7c77f7d1/pydantic/schema.py#L207
- json_schema["title"] = field.field_info.title or field_alias.title().replace(
- "_", " "
- )
- return json_schema
-
-
-def get_definitions(
- *,
- fields: Sequence[ModelField],
- model_name_map: ModelNameMap,
- separate_input_output_schemas: bool = True,
-) -> tuple[
- dict[tuple[ModelField, Literal["validation", "serialization"]], JsonSchemaValue],
- dict[str, dict[str, Any]],
-]:
- schema_generator = GenerateJsonSchema(ref_template=REF_TEMPLATE)
- validation_fields = [field for field in fields if field.mode == "validation"]
- serialization_fields = [field for field in fields if field.mode == "serialization"]
- flat_validation_models = get_flat_models_from_fields(
- validation_fields, known_models=set()
- )
- flat_serialization_models = get_flat_models_from_fields(
- serialization_fields, known_models=set()
- )
- flat_validation_model_fields = [
- ModelField(
- field_info=FieldInfo(annotation=model),
- name=model.__name__,
- mode="validation",
- )
- for model in flat_validation_models
- ]
- flat_serialization_model_fields = [
- ModelField(
- field_info=FieldInfo(annotation=model),
- name=model.__name__,
- mode="serialization",
- )
- for model in flat_serialization_models
- ]
- flat_model_fields = flat_validation_model_fields + flat_serialization_model_fields
- input_types = {f.type_ for f in fields}
- unique_flat_model_fields = {
- f for f in flat_model_fields if f.type_ not in input_types
- }
- inputs = [
- (
- field,
- (
- field.mode
- if (separate_input_output_schemas or _has_computed_fields(field))
- else "validation"
- ),
- field._type_adapter.core_schema,
- )
- for field in list(fields) + list(unique_flat_model_fields)
- ]
- field_mapping, definitions = schema_generator.generate_definitions(inputs=inputs)
- for item_def in cast(dict[str, dict[str, Any]], definitions).values():
- if "description" in item_def:
- item_description = cast(str, item_def["description"]).split("\f")[0]
- item_def["description"] = item_description
- new_mapping, new_definitions = _remap_definitions_and_field_mappings(
- model_name_map=model_name_map,
- definitions=definitions, # type: ignore[arg-type]
- field_mapping=field_mapping,
- )
- return new_mapping, new_definitions
-
-
-def _replace_refs(
- *,
- schema: dict[str, Any],
- old_name_to_new_name_map: dict[str, str],
-) -> dict[str, Any]:
- new_schema = deepcopy(schema)
- for key, value in new_schema.items():
- if key == "$ref":
- value = schema["$ref"]
- if isinstance(value, str):
- ref_name = schema["$ref"].split("/")[-1]
- if ref_name in old_name_to_new_name_map:
- new_name = old_name_to_new_name_map[ref_name]
- new_schema["$ref"] = REF_TEMPLATE.format(model=new_name)
- continue
- if isinstance(value, dict):
- new_schema[key] = _replace_refs(
- schema=value,
- old_name_to_new_name_map=old_name_to_new_name_map,
- )
- elif isinstance(value, list):
- new_value = []
- for item in value:
- if isinstance(item, dict):
- new_item = _replace_refs(
- schema=item,
- old_name_to_new_name_map=old_name_to_new_name_map,
- )
- new_value.append(new_item)
-
- else:
- new_value.append(item)
- new_schema[key] = new_value
- return new_schema
-
-
-def _remap_definitions_and_field_mappings(
- *,
- model_name_map: ModelNameMap,
- definitions: dict[str, Any],
- field_mapping: dict[
- tuple[ModelField, Literal["validation", "serialization"]], JsonSchemaValue
- ],
-) -> tuple[
- dict[tuple[ModelField, Literal["validation", "serialization"]], JsonSchemaValue],
- dict[str, Any],
-]:
- old_name_to_new_name_map = {}
- for field_key, schema in field_mapping.items():
- model = field_key[0].type_
- if model not in model_name_map or "$ref" not in schema:
- continue
- new_name = model_name_map[model]
- old_name = schema["$ref"].split("/")[-1]
- if old_name in {f"{new_name}-Input", f"{new_name}-Output"}:
- continue
- old_name_to_new_name_map[old_name] = new_name
-
- new_field_mapping: dict[
- tuple[ModelField, Literal["validation", "serialization"]], JsonSchemaValue
- ] = {}
- for field_key, schema in field_mapping.items():
- new_schema = _replace_refs(
- schema=schema,
- old_name_to_new_name_map=old_name_to_new_name_map,
- )
- new_field_mapping[field_key] = new_schema
-
- new_definitions = {}
- for key, value in definitions.items():
- if key in old_name_to_new_name_map:
- new_key = old_name_to_new_name_map[key]
- else:
- new_key = key
- new_value = _replace_refs(
- schema=value,
- old_name_to_new_name_map=old_name_to_new_name_map,
- )
- new_definitions[new_key] = new_value
- return new_field_mapping, new_definitions
-
-
-def is_scalar_field(field: ModelField) -> bool:
- from fastapi import params
-
- return shared.field_annotation_is_scalar(
- field.field_info.annotation
- ) and not isinstance(field.field_info, params.Body)
-
-
-def is_sequence_field(field: ModelField) -> bool:
- return shared.field_annotation_is_sequence(field.field_info.annotation)
-
-
-def is_scalar_sequence_field(field: ModelField) -> bool:
- return shared.field_annotation_is_scalar_sequence(field.field_info.annotation)
-
-
-def is_bytes_field(field: ModelField) -> bool:
- return shared.is_bytes_or_nonable_bytes_annotation(field.type_)
-
-
-def is_bytes_sequence_field(field: ModelField) -> bool:
- return shared.is_bytes_sequence_annotation(field.type_)
-
-
-def copy_field_info(*, field_info: FieldInfo, annotation: Any) -> FieldInfo:
- cls = type(field_info)
- merged_field_info = cls.from_annotation(annotation)
- new_field_info = copy(field_info)
- new_field_info.metadata = merged_field_info.metadata
- new_field_info.annotation = merged_field_info.annotation
- return new_field_info
-
-
-def serialize_sequence_value(*, field: ModelField, value: Any) -> Sequence[Any]:
- origin_type = get_origin(field.field_info.annotation) or field.field_info.annotation
- if origin_type is Union or origin_type is UnionType: # Handle optional sequences
- union_args = get_args(field.field_info.annotation)
- for union_arg in union_args:
- if union_arg is type(None):
- continue
- origin_type = get_origin(union_arg) or union_arg
- break
- assert issubclass(origin_type, shared.sequence_types) # type: ignore[arg-type]
- return shared.sequence_annotation_to_type[origin_type](value) # type: ignore[no-any-return,index]
-
-
-def get_missing_field_error(loc: tuple[str, ...]) -> dict[str, Any]:
- error = ValidationError.from_exception_data(
- "Field required", [{"type": "missing", "loc": loc, "input": {}}]
- ).errors(include_url=False)[0]
- error["input"] = None
- return error # type: ignore[return-value]
-
-
-def create_body_model(
- *, fields: Sequence[ModelField], model_name: str
-) -> type[BaseModel]:
- field_params = {f.name: (f.field_info.annotation, f.field_info) for f in fields}
- BodyModel: type[BaseModel] = create_model(model_name, **field_params) # type: ignore[call-overload]
- return BodyModel
-
-
-def get_model_fields(model: type[BaseModel]) -> list[ModelField]:
- model_fields: list[ModelField] = []
- for name, field_info in model.model_fields.items():
- type_ = field_info.annotation
- if lenient_issubclass(type_, (BaseModel, dict)) or is_dataclass(type_):
- model_config = None
- else:
- model_config = model.model_config
- model_fields.append(
- ModelField(
- field_info=field_info,
- name=name,
- config=model_config,
- )
- )
- return model_fields
-
-
-@lru_cache
-def get_cached_model_fields(model: type[BaseModel]) -> list[ModelField]:
- return get_model_fields(model) # type: ignore[return-value]
-
-
-# Duplicate of several schema functions from Pydantic v1 to make them compatible with
-# Pydantic v2 and allow mixing the models
-
-TypeModelOrEnum = Union[type["BaseModel"], type[Enum]]
-TypeModelSet = set[TypeModelOrEnum]
-
-
-def normalize_name(name: str) -> str:
- return re.sub(r"[^a-zA-Z0-9.\-_]", "_", name)
-
-
-def get_model_name_map(unique_models: TypeModelSet) -> dict[TypeModelOrEnum, str]:
- name_model_map = {}
- for model in unique_models:
- model_name = normalize_name(model.__name__)
- name_model_map[model_name] = model
- return {v: k for k, v in name_model_map.items()}
-
-
-def get_compat_model_name_map(fields: list[ModelField]) -> ModelNameMap:
- all_flat_models = set()
-
- v2_model_fields = [field for field in fields if isinstance(field, ModelField)]
- v2_flat_models = get_flat_models_from_fields(v2_model_fields, known_models=set())
- all_flat_models = all_flat_models.union(v2_flat_models) # type: ignore[arg-type]
-
- model_name_map = get_model_name_map(all_flat_models) # type: ignore[arg-type]
- return model_name_map
-
-
-def get_flat_models_from_model(
- model: type["BaseModel"], known_models: Union[TypeModelSet, None] = None
-) -> TypeModelSet:
- known_models = known_models or set()
- fields = get_model_fields(model)
- get_flat_models_from_fields(fields, known_models=known_models)
- return known_models
-
-
-def get_flat_models_from_annotation(
- annotation: Any, known_models: TypeModelSet
-) -> TypeModelSet:
- origin = get_origin(annotation)
- if origin is not None:
- for arg in get_args(annotation):
- if lenient_issubclass(arg, (BaseModel, Enum)) and arg not in known_models:
- known_models.add(arg)
- if lenient_issubclass(arg, BaseModel):
- get_flat_models_from_model(arg, known_models=known_models)
- else:
- get_flat_models_from_annotation(arg, known_models=known_models)
- return known_models
-
-
-def get_flat_models_from_field(
- field: ModelField, known_models: TypeModelSet
-) -> TypeModelSet:
- field_type = field.type_
- if lenient_issubclass(field_type, BaseModel):
- if field_type in known_models:
- return known_models
- known_models.add(field_type)
- get_flat_models_from_model(field_type, known_models=known_models)
- elif lenient_issubclass(field_type, Enum):
- known_models.add(field_type)
- else:
- get_flat_models_from_annotation(field_type, known_models=known_models)
- return known_models
-
-
-def get_flat_models_from_fields(
- fields: Sequence[ModelField], known_models: TypeModelSet
-) -> TypeModelSet:
- for field in fields:
- get_flat_models_from_field(field, known_models=known_models)
- return known_models
-
-
-def _regenerate_error_with_loc(
- *, errors: Sequence[Any], loc_prefix: tuple[Union[str, int], ...]
-) -> list[dict[str, Any]]:
- updated_loc_errors: list[Any] = [
- {**err, "loc": loc_prefix + err.get("loc", ())} for err in errors
- ]
-
- return updated_loc_errors
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/applications.py b/backend/.venv/lib/python3.12/site-packages/fastapi/applications.py
deleted file mode 100644
index 54175cb..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/applications.py
+++ /dev/null
@@ -1,4669 +0,0 @@
-from collections.abc import Awaitable, Coroutine, Sequence
-from enum import Enum
-from typing import (
- Annotated,
- Any,
- Callable,
- Optional,
- TypeVar,
- Union,
-)
-
-from annotated_doc import Doc
-from fastapi import routing
-from fastapi.datastructures import Default, DefaultPlaceholder
-from fastapi.exception_handlers import (
- http_exception_handler,
- request_validation_exception_handler,
- websocket_request_validation_exception_handler,
-)
-from fastapi.exceptions import RequestValidationError, WebSocketRequestValidationError
-from fastapi.logger import logger
-from fastapi.middleware.asyncexitstack import AsyncExitStackMiddleware
-from fastapi.openapi.docs import (
- get_redoc_html,
- get_swagger_ui_html,
- get_swagger_ui_oauth2_redirect_html,
-)
-from fastapi.openapi.utils import get_openapi
-from fastapi.params import Depends
-from fastapi.types import DecoratedCallable, IncEx
-from fastapi.utils import generate_unique_id
-from starlette.applications import Starlette
-from starlette.datastructures import State
-from starlette.exceptions import HTTPException
-from starlette.middleware import Middleware
-from starlette.middleware.base import BaseHTTPMiddleware
-from starlette.middleware.errors import ServerErrorMiddleware
-from starlette.middleware.exceptions import ExceptionMiddleware
-from starlette.requests import Request
-from starlette.responses import HTMLResponse, JSONResponse, Response
-from starlette.routing import BaseRoute
-from starlette.types import ASGIApp, ExceptionHandler, Lifespan, Receive, Scope, Send
-from typing_extensions import deprecated
-
-AppType = TypeVar("AppType", bound="FastAPI")
-
-
-class FastAPI(Starlette):
- """
- `FastAPI` app class, the main entrypoint to use FastAPI.
-
- Read more in the
- [FastAPI docs for First Steps](https://fastapi.tiangolo.com/tutorial/first-steps/).
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
- ```
- """
-
- def __init__(
- self: AppType,
- *,
- debug: Annotated[
- bool,
- Doc(
- """
- Boolean indicating if debug tracebacks should be returned on server
- errors.
-
- Read more in the
- [Starlette docs for Applications](https://www.starlette.dev/applications/#instantiating-the-application).
- """
- ),
- ] = False,
- routes: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- **Note**: you probably shouldn't use this parameter, it is inherited
- from Starlette and supported for compatibility.
-
- ---
-
- A list of routes to serve incoming HTTP and WebSocket requests.
- """
- ),
- deprecated(
- """
- You normally wouldn't use this parameter with FastAPI, it is inherited
- from Starlette and supported for compatibility.
-
- In FastAPI, you normally would use the *path operation methods*,
- like `app.get()`, `app.post()`, etc.
- """
- ),
- ] = None,
- title: Annotated[
- str,
- Doc(
- """
- The title of the API.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(title="ChimichangApp")
- ```
- """
- ),
- ] = "FastAPI",
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A short summary of the API.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(summary="Deadpond's favorite app. Nuff said.")
- ```
- """
- ),
- ] = None,
- description: Annotated[
- str,
- Doc(
- '''
- A description of the API. Supports Markdown (using
- [CommonMark syntax](https://commonmark.org/)).
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(
- description="""
- ChimichangApp API helps you do awesome stuff. 🚀
-
- ## Items
-
- You can **read items**.
-
- ## Users
-
- You will be able to:
-
- * **Create users** (_not implemented_).
- * **Read users** (_not implemented_).
-
- """
- )
- ```
- '''
- ),
- ] = "",
- version: Annotated[
- str,
- Doc(
- """
- The version of the API.
-
- **Note** This is the version of your application, not the version of
- the OpenAPI specification nor the version of FastAPI being used.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(version="0.0.1")
- ```
- """
- ),
- ] = "0.1.0",
- openapi_url: Annotated[
- Optional[str],
- Doc(
- """
- The URL where the OpenAPI schema will be served from.
-
- If you set it to `None`, no OpenAPI schema will be served publicly, and
- the default automatic endpoints `/docs` and `/redoc` will also be
- disabled.
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#openapi-url).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(openapi_url="/api/v1/openapi.json")
- ```
- """
- ),
- ] = "/openapi.json",
- openapi_tags: Annotated[
- Optional[list[dict[str, Any]]],
- Doc(
- """
- A list of tags used by OpenAPI, these are the same `tags` you can set
- in the *path operations*, like:
-
- * `@app.get("/users/", tags=["users"])`
- * `@app.get("/items/", tags=["items"])`
-
- The order of the tags can be used to specify the order shown in
- tools like Swagger UI, used in the automatic path `/docs`.
-
- It's not required to specify all the tags used.
-
- The tags that are not declared MAY be organized randomly or based
- on the tools' logic. Each tag name in the list MUST be unique.
-
- The value of each item is a `dict` containing:
-
- * `name`: The name of the tag.
- * `description`: A short description of the tag.
- [CommonMark syntax](https://commonmark.org/) MAY be used for rich
- text representation.
- * `externalDocs`: Additional external documentation for this tag. If
- provided, it would contain a `dict` with:
- * `description`: A short description of the target documentation.
- [CommonMark syntax](https://commonmark.org/) MAY be used for
- rich text representation.
- * `url`: The URL for the target documentation. Value MUST be in
- the form of a URL.
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-tags).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- tags_metadata = [
- {
- "name": "users",
- "description": "Operations with users. The **login** logic is also here.",
- },
- {
- "name": "items",
- "description": "Manage items. So _fancy_ they have their own docs.",
- "externalDocs": {
- "description": "Items external docs",
- "url": "https://fastapi.tiangolo.com/",
- },
- },
- ]
-
- app = FastAPI(openapi_tags=tags_metadata)
- ```
- """
- ),
- ] = None,
- servers: Annotated[
- Optional[list[dict[str, Union[str, Any]]]],
- Doc(
- """
- A `list` of `dict`s with connectivity information to a target server.
-
- You would use it, for example, if your application is served from
- different domains and you want to use the same Swagger UI in the
- browser to interact with each of them (instead of having multiple
- browser tabs open). Or if you want to leave fixed the possible URLs.
-
- If the servers `list` is not provided, or is an empty `list`, the
- `servers` property in the generated OpenAPI will be:
-
- * a `dict` with a `url` value of the application's mounting point
- (`root_path`) if it's different from `/`.
- * otherwise, the `servers` property will be omitted from the OpenAPI
- schema.
-
- Each item in the `list` is a `dict` containing:
-
- * `url`: A URL to the target host. This URL supports Server Variables
- and MAY be relative, to indicate that the host location is relative
- to the location where the OpenAPI document is being served. Variable
- substitutions will be made when a variable is named in `{`brackets`}`.
- * `description`: An optional string describing the host designated by
- the URL. [CommonMark syntax](https://commonmark.org/) MAY be used for
- rich text representation.
- * `variables`: A `dict` between a variable name and its value. The value
- is used for substitution in the server's URL template.
-
- Read more in the
- [FastAPI docs for Behind a Proxy](https://fastapi.tiangolo.com/advanced/behind-a-proxy/#additional-servers).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(
- servers=[
- {"url": "https://stag.example.com", "description": "Staging environment"},
- {"url": "https://prod.example.com", "description": "Production environment"},
- ]
- )
- ```
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of global dependencies, they will be applied to each
- *path operation*, including in sub-routers.
-
- Read more about it in the
- [FastAPI docs for Global Dependencies](https://fastapi.tiangolo.com/tutorial/dependencies/global-dependencies/).
-
- **Example**
-
- ```python
- from fastapi import Depends, FastAPI
-
- from .dependencies import func_dep_1, func_dep_2
-
- app = FastAPI(dependencies=[Depends(func_dep_1), Depends(func_dep_2)])
- ```
- """
- ),
- ] = None,
- default_response_class: Annotated[
- type[Response],
- Doc(
- """
- The default response class to be used.
-
- Read more in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#default-response-class).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
- from fastapi.responses import ORJSONResponse
-
- app = FastAPI(default_response_class=ORJSONResponse)
- ```
- """
- ),
- ] = Default(JSONResponse),
- redirect_slashes: Annotated[
- bool,
- Doc(
- """
- Whether to detect and redirect slashes in URLs when the client doesn't
- use the same format.
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(redirect_slashes=True) # the default
-
- @app.get("/items/")
- async def read_items():
- return [{"item_id": "Foo"}]
- ```
-
- With this app, if a client goes to `/items` (without a trailing slash),
- they will be automatically redirected with an HTTP status code of 307
- to `/items/`.
- """
- ),
- ] = True,
- docs_url: Annotated[
- Optional[str],
- Doc(
- """
- The path to the automatic interactive API documentation.
- It is handled in the browser by Swagger UI.
-
- The default URL is `/docs`. You can disable it by setting it to `None`.
-
- If `openapi_url` is set to `None`, this will be automatically disabled.
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#docs-urls).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(docs_url="/documentation", redoc_url=None)
- ```
- """
- ),
- ] = "/docs",
- redoc_url: Annotated[
- Optional[str],
- Doc(
- """
- The path to the alternative automatic interactive API documentation
- provided by ReDoc.
-
- The default URL is `/redoc`. You can disable it by setting it to `None`.
-
- If `openapi_url` is set to `None`, this will be automatically disabled.
-
- Read more in the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#docs-urls).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(docs_url="/documentation", redoc_url="redocumentation")
- ```
- """
- ),
- ] = "/redoc",
- swagger_ui_oauth2_redirect_url: Annotated[
- Optional[str],
- Doc(
- """
- The OAuth2 redirect endpoint for the Swagger UI.
-
- By default it is `/docs/oauth2-redirect`.
-
- This is only used if you use OAuth2 (with the "Authorize" button)
- with Swagger UI.
- """
- ),
- ] = "/docs/oauth2-redirect",
- swagger_ui_init_oauth: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- OAuth2 configuration for the Swagger UI, by default shown at `/docs`.
-
- Read more about the available configuration options in the
- [Swagger UI docs](https://swagger.io/docs/open-source-tools/swagger-ui/usage/oauth2/).
- """
- ),
- ] = None,
- middleware: Annotated[
- Optional[Sequence[Middleware]],
- Doc(
- """
- List of middleware to be added when creating the application.
-
- In FastAPI you would normally do this with `app.add_middleware()`
- instead.
-
- Read more in the
- [FastAPI docs for Middleware](https://fastapi.tiangolo.com/tutorial/middleware/).
- """
- ),
- ] = None,
- exception_handlers: Annotated[
- Optional[
- dict[
- Union[int, type[Exception]],
- Callable[[Request, Any], Coroutine[Any, Any, Response]],
- ]
- ],
- Doc(
- """
- A dictionary with handlers for exceptions.
-
- In FastAPI, you would normally use the decorator
- `@app.exception_handler()`.
-
- Read more in the
- [FastAPI docs for Handling Errors](https://fastapi.tiangolo.com/tutorial/handling-errors/).
- """
- ),
- ] = None,
- on_startup: Annotated[
- Optional[Sequence[Callable[[], Any]]],
- Doc(
- """
- A list of startup event handler functions.
-
- You should instead use the `lifespan` handlers.
-
- Read more in the [FastAPI docs for `lifespan`](https://fastapi.tiangolo.com/advanced/events/).
- """
- ),
- ] = None,
- on_shutdown: Annotated[
- Optional[Sequence[Callable[[], Any]]],
- Doc(
- """
- A list of shutdown event handler functions.
-
- You should instead use the `lifespan` handlers.
-
- Read more in the
- [FastAPI docs for `lifespan`](https://fastapi.tiangolo.com/advanced/events/).
- """
- ),
- ] = None,
- lifespan: Annotated[
- Optional[Lifespan[AppType]],
- Doc(
- """
- A `Lifespan` context manager handler. This replaces `startup` and
- `shutdown` functions with a single context manager.
-
- Read more in the
- [FastAPI docs for `lifespan`](https://fastapi.tiangolo.com/advanced/events/).
- """
- ),
- ] = None,
- terms_of_service: Annotated[
- Optional[str],
- Doc(
- """
- A URL to the Terms of Service for your API.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more at the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- app = FastAPI(terms_of_service="http://example.com/terms/")
- ```
- """
- ),
- ] = None,
- contact: Annotated[
- Optional[dict[str, Union[str, Any]]],
- Doc(
- """
- A dictionary with the contact information for the exposed API.
-
- It can contain several fields.
-
- * `name`: (`str`) The name of the contact person/organization.
- * `url`: (`str`) A URL pointing to the contact information. MUST be in
- the format of a URL.
- * `email`: (`str`) The email address of the contact person/organization.
- MUST be in the format of an email address.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more at the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- app = FastAPI(
- contact={
- "name": "Deadpoolio the Amazing",
- "url": "http://x-force.example.com/contact/",
- "email": "dp@x-force.example.com",
- }
- )
- ```
- """
- ),
- ] = None,
- license_info: Annotated[
- Optional[dict[str, Union[str, Any]]],
- Doc(
- """
- A dictionary with the license information for the exposed API.
-
- It can contain several fields.
-
- * `name`: (`str`) **REQUIRED** (if a `license_info` is set). The
- license name used for the API.
- * `identifier`: (`str`) An [SPDX](https://spdx.dev/) license expression
- for the API. The `identifier` field is mutually exclusive of the `url`
- field. Available since OpenAPI 3.1.0, FastAPI 0.99.0.
- * `url`: (`str`) A URL to the license used for the API. This MUST be
- the format of a URL.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more at the
- [FastAPI docs for Metadata and Docs URLs](https://fastapi.tiangolo.com/tutorial/metadata/#metadata-for-api).
-
- **Example**
-
- ```python
- app = FastAPI(
- license_info={
- "name": "Apache 2.0",
- "url": "https://www.apache.org/licenses/LICENSE-2.0.html",
- }
- )
- ```
- """
- ),
- ] = None,
- openapi_prefix: Annotated[
- str,
- Doc(
- """
- A URL prefix for the OpenAPI URL.
- """
- ),
- deprecated(
- """
- "openapi_prefix" has been deprecated in favor of "root_path", which
- follows more closely the ASGI standard, is simpler, and more
- automatic.
- """
- ),
- ] = "",
- root_path: Annotated[
- str,
- Doc(
- """
- A path prefix handled by a proxy that is not seen by the application
- but is seen by external clients, which affects things like Swagger UI.
-
- Read more about it at the
- [FastAPI docs for Behind a Proxy](https://fastapi.tiangolo.com/advanced/behind-a-proxy/).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(root_path="/api/v1")
- ```
- """
- ),
- ] = "",
- root_path_in_servers: Annotated[
- bool,
- Doc(
- """
- To disable automatically generating the URLs in the `servers` field
- in the autogenerated OpenAPI using the `root_path`.
-
- Read more about it in the
- [FastAPI docs for Behind a Proxy](https://fastapi.tiangolo.com/advanced/behind-a-proxy/#disable-automatic-server-from-root_path).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI(root_path_in_servers=False)
- ```
- """
- ),
- ] = True,
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses to be shown in OpenAPI.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Additional Responses in OpenAPI](https://fastapi.tiangolo.com/advanced/additional-responses/).
-
- And in the
- [FastAPI docs for Bigger Applications](https://fastapi.tiangolo.com/tutorial/bigger-applications/#include-an-apirouter-with-a-custom-prefix-tags-responses-and-dependencies).
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- OpenAPI callbacks that should apply to all *path operations*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- webhooks: Annotated[
- Optional[routing.APIRouter],
- Doc(
- """
- Add OpenAPI webhooks. This is similar to `callbacks` but it doesn't
- depend on specific *path operations*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- **Note**: This is available since OpenAPI 3.1.0, FastAPI 0.99.0.
-
- Read more about it in the
- [FastAPI docs for OpenAPI Webhooks](https://fastapi.tiangolo.com/advanced/openapi-webhooks/).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark all *path operations* as deprecated. You probably don't need it,
- but it's available.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- To include (or not) all the *path operations* in the generated OpenAPI.
- You probably don't need it, but it's available.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- swagger_ui_parameters: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Parameters to configure Swagger UI, the autogenerated interactive API
- documentation (by default at `/docs`).
-
- Read more about it in the
- [FastAPI docs about how to Configure Swagger UI](https://fastapi.tiangolo.com/how-to/configure-swagger-ui/).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- separate_input_output_schemas: Annotated[
- bool,
- Doc(
- """
- Whether to generate separate OpenAPI schemas for request body and
- response body when the results would be more precise.
-
- This is particularly useful when automatically generating clients.
-
- For example, if you have a model like:
-
- ```python
- from pydantic import BaseModel
-
- class Item(BaseModel):
- name: str
- tags: list[str] = []
- ```
-
- When `Item` is used for input, a request body, `tags` is not required,
- the client doesn't have to provide it.
-
- But when using `Item` for output, for a response body, `tags` is always
- available because it has a default value, even if it's just an empty
- list. So, the client should be able to always expect it.
-
- In this case, there would be two different schemas, one for input and
- another one for output.
- """
- ),
- ] = True,
- openapi_external_docs: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- This field allows you to provide additional external documentation links.
- If provided, it must be a dictionary containing:
-
- * `description`: A brief description of the external documentation.
- * `url`: The URL pointing to the external documentation. The value **MUST**
- be a valid URL format.
-
- **Example**:
-
- ```python
- from fastapi import FastAPI
-
- external_docs = {
- "description": "Detailed API Reference",
- "url": "https://example.com/api-docs",
- }
-
- app = FastAPI(openapi_external_docs=external_docs)
- ```
- """
- ),
- ] = None,
- **extra: Annotated[
- Any,
- Doc(
- """
- Extra keyword arguments to be stored in the app, not used by FastAPI
- anywhere.
- """
- ),
- ],
- ) -> None:
- self.debug = debug
- self.title = title
- self.summary = summary
- self.description = description
- self.version = version
- self.terms_of_service = terms_of_service
- self.contact = contact
- self.license_info = license_info
- self.openapi_url = openapi_url
- self.openapi_tags = openapi_tags
- self.root_path_in_servers = root_path_in_servers
- self.docs_url = docs_url
- self.redoc_url = redoc_url
- self.swagger_ui_oauth2_redirect_url = swagger_ui_oauth2_redirect_url
- self.swagger_ui_init_oauth = swagger_ui_init_oauth
- self.swagger_ui_parameters = swagger_ui_parameters
- self.servers = servers or []
- self.separate_input_output_schemas = separate_input_output_schemas
- self.openapi_external_docs = openapi_external_docs
- self.extra = extra
- self.openapi_version: Annotated[
- str,
- Doc(
- """
- The version string of OpenAPI.
-
- FastAPI will generate OpenAPI version 3.1.0, and will output that as
- the OpenAPI version. But some tools, even though they might be
- compatible with OpenAPI 3.1.0, might not recognize it as a valid.
-
- So you could override this value to trick those tools into using
- the generated OpenAPI. Have in mind that this is a hack. But if you
- avoid using features added in OpenAPI 3.1.0, it might work for your
- use case.
-
- This is not passed as a parameter to the `FastAPI` class to avoid
- giving the false idea that FastAPI would generate a different OpenAPI
- schema. It is only available as an attribute.
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
-
- app.openapi_version = "3.0.2"
- ```
- """
- ),
- ] = "3.1.0"
- self.openapi_schema: Optional[dict[str, Any]] = None
- if self.openapi_url:
- assert self.title, "A title must be provided for OpenAPI, e.g.: 'My API'"
- assert self.version, "A version must be provided for OpenAPI, e.g.: '2.1.0'"
- # TODO: remove when discarding the openapi_prefix parameter
- if openapi_prefix:
- logger.warning(
- '"openapi_prefix" has been deprecated in favor of "root_path", which '
- "follows more closely the ASGI standard, is simpler, and more "
- "automatic. Check the docs at "
- "https://fastapi.tiangolo.com/advanced/sub-applications/"
- )
- self.webhooks: Annotated[
- routing.APIRouter,
- Doc(
- """
- The `app.webhooks` attribute is an `APIRouter` with the *path
- operations* that will be used just for documentation of webhooks.
-
- Read more about it in the
- [FastAPI docs for OpenAPI Webhooks](https://fastapi.tiangolo.com/advanced/openapi-webhooks/).
- """
- ),
- ] = webhooks or routing.APIRouter()
- self.root_path = root_path or openapi_prefix
- self.state: Annotated[
- State,
- Doc(
- """
- A state object for the application. This is the same object for the
- entire application, it doesn't change from request to request.
-
- You normally wouldn't use this in FastAPI, for most of the cases you
- would instead use FastAPI dependencies.
-
- This is simply inherited from Starlette.
-
- Read more about it in the
- [Starlette docs for Applications](https://www.starlette.dev/applications/#storing-state-on-the-app-instance).
- """
- ),
- ] = State()
- self.dependency_overrides: Annotated[
- dict[Callable[..., Any], Callable[..., Any]],
- Doc(
- """
- A dictionary with overrides for the dependencies.
-
- Each key is the original dependency callable, and the value is the
- actual dependency that should be called.
-
- This is for testing, to replace expensive dependencies with testing
- versions.
-
- Read more about it in the
- [FastAPI docs for Testing Dependencies with Overrides](https://fastapi.tiangolo.com/advanced/testing-dependencies/).
- """
- ),
- ] = {}
- self.router: routing.APIRouter = routing.APIRouter(
- routes=routes,
- redirect_slashes=redirect_slashes,
- dependency_overrides_provider=self,
- on_startup=on_startup,
- on_shutdown=on_shutdown,
- lifespan=lifespan,
- default_response_class=default_response_class,
- dependencies=dependencies,
- callbacks=callbacks,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- responses=responses,
- generate_unique_id_function=generate_unique_id_function,
- )
- self.exception_handlers: dict[
- Any, Callable[[Request, Any], Union[Response, Awaitable[Response]]]
- ] = {} if exception_handlers is None else dict(exception_handlers)
- self.exception_handlers.setdefault(HTTPException, http_exception_handler)
- self.exception_handlers.setdefault(
- RequestValidationError, request_validation_exception_handler
- )
- self.exception_handlers.setdefault(
- WebSocketRequestValidationError,
- # Starlette still has incorrect type specification for the handlers
- websocket_request_validation_exception_handler, # type: ignore
- )
-
- self.user_middleware: list[Middleware] = (
- [] if middleware is None else list(middleware)
- )
- self.middleware_stack: Union[ASGIApp, None] = None
- self.setup()
-
- def build_middleware_stack(self) -> ASGIApp:
- # Duplicate/override from Starlette to add AsyncExitStackMiddleware
- # inside of ExceptionMiddleware, inside of custom user middlewares
- debug = self.debug
- error_handler = None
- exception_handlers: dict[Any, ExceptionHandler] = {}
-
- for key, value in self.exception_handlers.items():
- if key in (500, Exception):
- error_handler = value
- else:
- exception_handlers[key] = value
-
- middleware = (
- [Middleware(ServerErrorMiddleware, handler=error_handler, debug=debug)]
- + self.user_middleware
- + [
- Middleware(
- ExceptionMiddleware, handlers=exception_handlers, debug=debug
- ),
- # Add FastAPI-specific AsyncExitStackMiddleware for closing files.
- # Before this was also used for closing dependencies with yield but
- # those now have their own AsyncExitStack, to properly support
- # streaming responses while keeping compatibility with the previous
- # versions (as of writing 0.117.1) that allowed doing
- # except HTTPException inside a dependency with yield.
- # This needs to happen after user middlewares because those create a
- # new contextvars context copy by using a new AnyIO task group.
- # This AsyncExitStack preserves the context for contextvars, not
- # strictly necessary for closing files but it was one of the original
- # intentions.
- # If the AsyncExitStack lived outside of the custom middlewares and
- # contextvars were set, for example in a dependency with 'yield'
- # in that internal contextvars context, the values would not be
- # available in the outer context of the AsyncExitStack.
- # By placing the middleware and the AsyncExitStack here, inside all
- # user middlewares, the same context is used.
- # This is currently not needed, only for closing files, but used to be
- # important when dependencies with yield were closed here.
- Middleware(AsyncExitStackMiddleware),
- ]
- )
-
- app = self.router
- for cls, args, kwargs in reversed(middleware):
- app = cls(app, *args, **kwargs)
- return app
-
- def openapi(self) -> dict[str, Any]:
- """
- Generate the OpenAPI schema of the application. This is called by FastAPI
- internally.
-
- The first time it is called it stores the result in the attribute
- `app.openapi_schema`, and next times it is called, it just returns that same
- result. To avoid the cost of generating the schema every time.
-
- If you need to modify the generated OpenAPI schema, you could modify it.
-
- Read more in the
- [FastAPI docs for OpenAPI](https://fastapi.tiangolo.com/how-to/extending-openapi/).
- """
- if not self.openapi_schema:
- self.openapi_schema = get_openapi(
- title=self.title,
- version=self.version,
- openapi_version=self.openapi_version,
- summary=self.summary,
- description=self.description,
- terms_of_service=self.terms_of_service,
- contact=self.contact,
- license_info=self.license_info,
- routes=self.routes,
- webhooks=self.webhooks.routes,
- tags=self.openapi_tags,
- servers=self.servers,
- separate_input_output_schemas=self.separate_input_output_schemas,
- external_docs=self.openapi_external_docs,
- )
- return self.openapi_schema
-
- def setup(self) -> None:
- if self.openapi_url:
- urls = (server_data.get("url") for server_data in self.servers)
- server_urls = {url for url in urls if url}
-
- async def openapi(req: Request) -> JSONResponse:
- root_path = req.scope.get("root_path", "").rstrip("/")
- if root_path not in server_urls:
- if root_path and self.root_path_in_servers:
- self.servers.insert(0, {"url": root_path})
- server_urls.add(root_path)
- return JSONResponse(self.openapi())
-
- self.add_route(self.openapi_url, openapi, include_in_schema=False)
- if self.openapi_url and self.docs_url:
-
- async def swagger_ui_html(req: Request) -> HTMLResponse:
- root_path = req.scope.get("root_path", "").rstrip("/")
- openapi_url = root_path + self.openapi_url
- oauth2_redirect_url = self.swagger_ui_oauth2_redirect_url
- if oauth2_redirect_url:
- oauth2_redirect_url = root_path + oauth2_redirect_url
- return get_swagger_ui_html(
- openapi_url=openapi_url,
- title=f"{self.title} - Swagger UI",
- oauth2_redirect_url=oauth2_redirect_url,
- init_oauth=self.swagger_ui_init_oauth,
- swagger_ui_parameters=self.swagger_ui_parameters,
- )
-
- self.add_route(self.docs_url, swagger_ui_html, include_in_schema=False)
-
- if self.swagger_ui_oauth2_redirect_url:
-
- async def swagger_ui_redirect(req: Request) -> HTMLResponse:
- return get_swagger_ui_oauth2_redirect_html()
-
- self.add_route(
- self.swagger_ui_oauth2_redirect_url,
- swagger_ui_redirect,
- include_in_schema=False,
- )
- if self.openapi_url and self.redoc_url:
-
- async def redoc_html(req: Request) -> HTMLResponse:
- root_path = req.scope.get("root_path", "").rstrip("/")
- openapi_url = root_path + self.openapi_url
- return get_redoc_html(
- openapi_url=openapi_url, title=f"{self.title} - ReDoc"
- )
-
- self.add_route(self.redoc_url, redoc_html, include_in_schema=False)
-
- async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
- if self.root_path:
- scope["root_path"] = self.root_path
- await super().__call__(scope, receive, send)
-
- def add_api_route(
- self,
- path: str,
- endpoint: Callable[..., Any],
- *,
- response_model: Any = Default(None),
- status_code: Optional[int] = None,
- tags: Optional[list[Union[str, Enum]]] = None,
- dependencies: Optional[Sequence[Depends]] = None,
- summary: Optional[str] = None,
- description: Optional[str] = None,
- response_description: str = "Successful Response",
- responses: Optional[dict[Union[int, str], dict[str, Any]]] = None,
- deprecated: Optional[bool] = None,
- methods: Optional[list[str]] = None,
- operation_id: Optional[str] = None,
- response_model_include: Optional[IncEx] = None,
- response_model_exclude: Optional[IncEx] = None,
- response_model_by_alias: bool = True,
- response_model_exclude_unset: bool = False,
- response_model_exclude_defaults: bool = False,
- response_model_exclude_none: bool = False,
- include_in_schema: bool = True,
- response_class: Union[type[Response], DefaultPlaceholder] = Default(
- JSONResponse
- ),
- name: Optional[str] = None,
- openapi_extra: Optional[dict[str, Any]] = None,
- generate_unique_id_function: Callable[[routing.APIRoute], str] = Default(
- generate_unique_id
- ),
- ) -> None:
- self.router.add_api_route(
- path,
- endpoint=endpoint,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- methods=methods,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def api_route(
- self,
- path: str,
- *,
- response_model: Any = Default(None),
- status_code: Optional[int] = None,
- tags: Optional[list[Union[str, Enum]]] = None,
- dependencies: Optional[Sequence[Depends]] = None,
- summary: Optional[str] = None,
- description: Optional[str] = None,
- response_description: str = "Successful Response",
- responses: Optional[dict[Union[int, str], dict[str, Any]]] = None,
- deprecated: Optional[bool] = None,
- methods: Optional[list[str]] = None,
- operation_id: Optional[str] = None,
- response_model_include: Optional[IncEx] = None,
- response_model_exclude: Optional[IncEx] = None,
- response_model_by_alias: bool = True,
- response_model_exclude_unset: bool = False,
- response_model_exclude_defaults: bool = False,
- response_model_exclude_none: bool = False,
- include_in_schema: bool = True,
- response_class: type[Response] = Default(JSONResponse),
- name: Optional[str] = None,
- openapi_extra: Optional[dict[str, Any]] = None,
- generate_unique_id_function: Callable[[routing.APIRoute], str] = Default(
- generate_unique_id
- ),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- def decorator(func: DecoratedCallable) -> DecoratedCallable:
- self.router.add_api_route(
- path,
- func,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- methods=methods,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
- return func
-
- return decorator
-
- def add_api_websocket_route(
- self,
- path: str,
- endpoint: Callable[..., Any],
- name: Optional[str] = None,
- *,
- dependencies: Optional[Sequence[Depends]] = None,
- ) -> None:
- self.router.add_api_websocket_route(
- path,
- endpoint,
- name=name,
- dependencies=dependencies,
- )
-
- def websocket(
- self,
- path: Annotated[
- str,
- Doc(
- """
- WebSocket path.
- """
- ),
- ],
- name: Annotated[
- Optional[str],
- Doc(
- """
- A name for the WebSocket. Only used internally.
- """
- ),
- ] = None,
- *,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be used for this
- WebSocket.
-
- Read more about it in the
- [FastAPI docs for WebSockets](https://fastapi.tiangolo.com/advanced/websockets/).
- """
- ),
- ] = None,
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Decorate a WebSocket function.
-
- Read more about it in the
- [FastAPI docs for WebSockets](https://fastapi.tiangolo.com/advanced/websockets/).
-
- **Example**
-
- ```python
- from fastapi import FastAPI, WebSocket
-
- app = FastAPI()
-
- @app.websocket("/ws")
- async def websocket_endpoint(websocket: WebSocket):
- await websocket.accept()
- while True:
- data = await websocket.receive_text()
- await websocket.send_text(f"Message text was: {data}")
- ```
- """
-
- def decorator(func: DecoratedCallable) -> DecoratedCallable:
- self.add_api_websocket_route(
- path,
- func,
- name=name,
- dependencies=dependencies,
- )
- return func
-
- return decorator
-
- def include_router(
- self,
- router: Annotated[routing.APIRouter, Doc("The `APIRouter` to include.")],
- *,
- prefix: Annotated[str, Doc("An optional path prefix for the router.")] = "",
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to all the *path operations* in this
- router.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to all the
- *path operations* in this router.
-
- Read more about it in the
- [FastAPI docs for Bigger Applications - Multiple Files](https://fastapi.tiangolo.com/tutorial/bigger-applications/#include-an-apirouter-with-a-custom-prefix-tags-responses-and-dependencies).
-
- **Example**
-
- ```python
- from fastapi import Depends, FastAPI
-
- from .dependencies import get_token_header
- from .internal import admin
-
- app = FastAPI()
-
- app.include_router(
- admin.router,
- dependencies=[Depends(get_token_header)],
- )
- ```
- """
- ),
- ] = None,
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses to be shown in OpenAPI.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Additional Responses in OpenAPI](https://fastapi.tiangolo.com/advanced/additional-responses/).
-
- And in the
- [FastAPI docs for Bigger Applications](https://fastapi.tiangolo.com/tutorial/bigger-applications/#include-an-apirouter-with-a-custom-prefix-tags-responses-and-dependencies).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark all the *path operations* in this router as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- from .internal import old_api
-
- app = FastAPI()
-
- app.include_router(
- old_api.router,
- deprecated=True,
- )
- ```
- """
- ),
- ] = None,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include (or not) all the *path operations* in this router in the
- generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
-
- from .internal import old_api
-
- app = FastAPI()
-
- app.include_router(
- old_api.router,
- include_in_schema=False,
- )
- ```
- """
- ),
- ] = True,
- default_response_class: Annotated[
- type[Response],
- Doc(
- """
- Default response class to be used for the *path operations* in this
- router.
-
- Read more in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#default-response-class).
-
- **Example**
-
- ```python
- from fastapi import FastAPI
- from fastapi.responses import ORJSONResponse
-
- from .internal import old_api
-
- app = FastAPI()
-
- app.include_router(
- old_api.router,
- default_response_class=ORJSONResponse,
- )
- ```
- """
- ),
- ] = Default(JSONResponse),
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> None:
- """
- Include an `APIRouter` in the same app.
-
- Read more about it in the
- [FastAPI docs for Bigger Applications](https://fastapi.tiangolo.com/tutorial/bigger-applications/).
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- from .users import users_router
-
- app = FastAPI()
-
- app.include_router(users_router)
- ```
- """
- self.router.include_router(
- router,
- prefix=prefix,
- tags=tags,
- dependencies=dependencies,
- responses=responses,
- deprecated=deprecated,
- include_in_schema=include_in_schema,
- default_response_class=default_response_class,
- callbacks=callbacks,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def get(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP GET operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
-
- @app.get("/items/")
- def read_items():
- return [{"name": "Empanada"}, {"name": "Arepa"}]
- ```
- """
- return self.router.get(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def put(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP PUT operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
- from pydantic import BaseModel
-
- class Item(BaseModel):
- name: str
- description: str | None = None
-
- app = FastAPI()
-
- @app.put("/items/{item_id}")
- def replace_item(item_id: str, item: Item):
- return {"message": "Item replaced", "id": item_id}
- ```
- """
- return self.router.put(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def post(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP POST operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
- from pydantic import BaseModel
-
- class Item(BaseModel):
- name: str
- description: str | None = None
-
- app = FastAPI()
-
- @app.post("/items/")
- def create_item(item: Item):
- return {"message": "Item created"}
- ```
- """
- return self.router.post(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def delete(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP DELETE operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
-
- @app.delete("/items/{item_id}")
- def delete_item(item_id: str):
- return {"message": "Item deleted"}
- ```
- """
- return self.router.delete(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def options(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP OPTIONS operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
-
- @app.options("/items/")
- def get_item_options():
- return {"additions": ["Aji", "Guacamole"]}
- ```
- """
- return self.router.options(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def head(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP HEAD operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI, Response
-
- app = FastAPI()
-
- @app.head("/items/", status_code=204)
- def get_items_headers(response: Response):
- response.headers["X-Cat-Dog"] = "Alone in the world"
- ```
- """
- return self.router.head(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def patch(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP PATCH operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
- from pydantic import BaseModel
-
- class Item(BaseModel):
- name: str
- description: str | None = None
-
- app = FastAPI()
-
- @app.patch("/items/")
- def update_item(item: Item):
- return {"message": "Item updated in place"}
- ```
- """
- return self.router.patch(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def trace(
- self,
- path: Annotated[
- str,
- Doc(
- """
- The URL path to be used for this *path operation*.
-
- For example, in `http://example.com/items`, the path is `/items`.
- """
- ),
- ],
- *,
- response_model: Annotated[
- Any,
- Doc(
- """
- The type to use for the response.
-
- It could be any valid Pydantic *field* type. So, it doesn't have to
- be a Pydantic model, it could be other things, like a `list`, `dict`,
- etc.
-
- It will be used for:
-
- * Documentation: the generated OpenAPI (and the UI at `/docs`) will
- show it as the response (JSON Schema).
- * Serialization: you could return an arbitrary object and the
- `response_model` would be used to serialize that object into the
- corresponding JSON.
- * Filtering: the JSON sent to the client will only contain the data
- (fields) defined in the `response_model`. If you returned an object
- that contains an attribute `password` but the `response_model` does
- not include that field, the JSON sent to the client would not have
- that `password`.
- * Validation: whatever you return will be serialized with the
- `response_model`, converting any data as necessary to generate the
- corresponding JSON. But if the data in the object returned is not
- valid, that would mean a violation of the contract with the client,
- so it's an error from the API developer. So, FastAPI will raise an
- error and return a 500 error code (Internal Server Error).
-
- Read more about it in the
- [FastAPI docs for Response Model](https://fastapi.tiangolo.com/tutorial/response-model/).
- """
- ),
- ] = Default(None),
- status_code: Annotated[
- Optional[int],
- Doc(
- """
- The default status code to be used for the response.
-
- You could override the status code by returning a response directly.
-
- Read more about it in the
- [FastAPI docs for Response Status Code](https://fastapi.tiangolo.com/tutorial/response-status-code/).
- """
- ),
- ] = None,
- tags: Annotated[
- Optional[list[Union[str, Enum]]],
- Doc(
- """
- A list of tags to be applied to the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/#tags).
- """
- ),
- ] = None,
- dependencies: Annotated[
- Optional[Sequence[Depends]],
- Doc(
- """
- A list of dependencies (using `Depends()`) to be applied to the
- *path operation*.
-
- Read more about it in the
- [FastAPI docs for Dependencies in path operation decorators](https://fastapi.tiangolo.com/tutorial/dependencies/dependencies-in-path-operation-decorators/).
- """
- ),
- ] = None,
- summary: Annotated[
- Optional[str],
- Doc(
- """
- A summary for the *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- description: Annotated[
- Optional[str],
- Doc(
- """
- A description for the *path operation*.
-
- If not provided, it will be extracted automatically from the docstring
- of the *path operation function*.
-
- It can contain Markdown.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Path Operation Configuration](https://fastapi.tiangolo.com/tutorial/path-operation-configuration/).
- """
- ),
- ] = None,
- response_description: Annotated[
- str,
- Doc(
- """
- The description for the default response.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = "Successful Response",
- responses: Annotated[
- Optional[dict[Union[int, str], dict[str, Any]]],
- Doc(
- """
- Additional responses that could be returned by this *path operation*.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- deprecated: Annotated[
- Optional[bool],
- Doc(
- """
- Mark this *path operation* as deprecated.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
- """
- ),
- ] = None,
- operation_id: Annotated[
- Optional[str],
- Doc(
- """
- Custom operation ID to be used by this *path operation*.
-
- By default, it is generated automatically.
-
- If you provide a custom operation ID, you need to make sure it is
- unique for the whole API.
-
- You can customize the
- operation ID generation with the parameter
- `generate_unique_id_function` in the `FastAPI` class.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = None,
- response_model_include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to include only certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Configuration passed to Pydantic to exclude certain fields in the
- response data.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = None,
- response_model_by_alias: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response model
- should be serialized by alias when an alias is used.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_include-and-response_model_exclude).
- """
- ),
- ] = True,
- response_model_exclude_unset: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that were not set and
- have their default values. This is different from
- `response_model_exclude_defaults` in that if the fields are set,
- they will be included in the response, even if the value is the same
- as the default.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data
- should have all the fields, including the ones that have the same value
- as the default. This is different from `response_model_exclude_unset`
- in that if the fields are set but contain the same default values,
- they will be excluded from the response.
-
- When `True`, default values are omitted from the response.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#use-the-response_model_exclude_unset-parameter).
- """
- ),
- ] = False,
- response_model_exclude_none: Annotated[
- bool,
- Doc(
- """
- Configuration passed to Pydantic to define if the response data should
- exclude fields set to `None`.
-
- This is much simpler (less smart) than `response_model_exclude_unset`
- and `response_model_exclude_defaults`. You probably want to use one of
- those two instead of this one, as those allow returning `None` values
- when it makes sense.
-
- Read more about it in the
- [FastAPI docs for Response Model - Return Type](https://fastapi.tiangolo.com/tutorial/response-model/#response_model_exclude_none).
- """
- ),
- ] = False,
- include_in_schema: Annotated[
- bool,
- Doc(
- """
- Include this *path operation* in the generated OpenAPI schema.
-
- This affects the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for Query Parameters and String Validations](https://fastapi.tiangolo.com/tutorial/query-params-str-validations/#exclude-parameters-from-openapi).
- """
- ),
- ] = True,
- response_class: Annotated[
- type[Response],
- Doc(
- """
- Response class to be used for this *path operation*.
-
- This will not be used if you return a response directly.
-
- Read more about it in the
- [FastAPI docs for Custom Response - HTML, Stream, File, others](https://fastapi.tiangolo.com/advanced/custom-response/#redirectresponse).
- """
- ),
- ] = Default(JSONResponse),
- name: Annotated[
- Optional[str],
- Doc(
- """
- Name for this *path operation*. Only used internally.
- """
- ),
- ] = None,
- callbacks: Annotated[
- Optional[list[BaseRoute]],
- Doc(
- """
- List of *path operations* that will be used as OpenAPI callbacks.
-
- This is only for OpenAPI documentation, the callbacks won't be used
- directly.
-
- It will be added to the generated OpenAPI (e.g. visible at `/docs`).
-
- Read more about it in the
- [FastAPI docs for OpenAPI Callbacks](https://fastapi.tiangolo.com/advanced/openapi-callbacks/).
- """
- ),
- ] = None,
- openapi_extra: Annotated[
- Optional[dict[str, Any]],
- Doc(
- """
- Extra metadata to be included in the OpenAPI schema for this *path
- operation*.
-
- Read more about it in the
- [FastAPI docs for Path Operation Advanced Configuration](https://fastapi.tiangolo.com/advanced/path-operation-advanced-configuration/#custom-openapi-path-operation-schema).
- """
- ),
- ] = None,
- generate_unique_id_function: Annotated[
- Callable[[routing.APIRoute], str],
- Doc(
- """
- Customize the function used to generate unique IDs for the *path
- operations* shown in the generated OpenAPI.
-
- This is particularly useful when automatically generating clients or
- SDKs for your API.
-
- Read more about it in the
- [FastAPI docs about how to Generate Clients](https://fastapi.tiangolo.com/advanced/generate-clients/#custom-generate-unique-id-function).
- """
- ),
- ] = Default(generate_unique_id),
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a *path operation* using an HTTP TRACE operation.
-
- ## Example
-
- ```python
- from fastapi import FastAPI
-
- app = FastAPI()
-
- @app.trace("/items/{item_id}")
- def trace_item(item_id: str):
- return None
- ```
- """
- return self.router.trace(
- path,
- response_model=response_model,
- status_code=status_code,
- tags=tags,
- dependencies=dependencies,
- summary=summary,
- description=description,
- response_description=response_description,
- responses=responses,
- deprecated=deprecated,
- operation_id=operation_id,
- response_model_include=response_model_include,
- response_model_exclude=response_model_exclude,
- response_model_by_alias=response_model_by_alias,
- response_model_exclude_unset=response_model_exclude_unset,
- response_model_exclude_defaults=response_model_exclude_defaults,
- response_model_exclude_none=response_model_exclude_none,
- include_in_schema=include_in_schema,
- response_class=response_class,
- name=name,
- callbacks=callbacks,
- openapi_extra=openapi_extra,
- generate_unique_id_function=generate_unique_id_function,
- )
-
- def websocket_route(
- self, path: str, name: Union[str, None] = None
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- def decorator(func: DecoratedCallable) -> DecoratedCallable:
- self.router.add_websocket_route(path, func, name=name)
- return func
-
- return decorator
-
- @deprecated(
- """
- on_event is deprecated, use lifespan event handlers instead.
-
- Read more about it in the
- [FastAPI docs for Lifespan Events](https://fastapi.tiangolo.com/advanced/events/).
- """
- )
- def on_event(
- self,
- event_type: Annotated[
- str,
- Doc(
- """
- The type of event. `startup` or `shutdown`.
- """
- ),
- ],
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add an event handler for the application.
-
- `on_event` is deprecated, use `lifespan` event handlers instead.
-
- Read more about it in the
- [FastAPI docs for Lifespan Events](https://fastapi.tiangolo.com/advanced/events/#alternative-events-deprecated).
- """
- return self.router.on_event(event_type)
-
- def middleware(
- self,
- middleware_type: Annotated[
- str,
- Doc(
- """
- The type of middleware. Currently only supports `http`.
- """
- ),
- ],
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add a middleware to the application.
-
- Read more about it in the
- [FastAPI docs for Middleware](https://fastapi.tiangolo.com/tutorial/middleware/).
-
- ## Example
-
- ```python
- import time
- from typing import Awaitable, Callable
-
- from fastapi import FastAPI, Request, Response
-
- app = FastAPI()
-
-
- @app.middleware("http")
- async def add_process_time_header(
- request: Request, call_next: Callable[[Request], Awaitable[Response]]
- ) -> Response:
- start_time = time.time()
- response = await call_next(request)
- process_time = time.time() - start_time
- response.headers["X-Process-Time"] = str(process_time)
- return response
- ```
- """
-
- def decorator(func: DecoratedCallable) -> DecoratedCallable:
- self.add_middleware(BaseHTTPMiddleware, dispatch=func)
- return func
-
- return decorator
-
- def exception_handler(
- self,
- exc_class_or_status_code: Annotated[
- Union[int, type[Exception]],
- Doc(
- """
- The Exception class this would handle, or a status code.
- """
- ),
- ],
- ) -> Callable[[DecoratedCallable], DecoratedCallable]:
- """
- Add an exception handler to the app.
-
- Read more about it in the
- [FastAPI docs for Handling Errors](https://fastapi.tiangolo.com/tutorial/handling-errors/).
-
- ## Example
-
- ```python
- from fastapi import FastAPI, Request
- from fastapi.responses import JSONResponse
-
-
- class UnicornException(Exception):
- def __init__(self, name: str):
- self.name = name
-
-
- app = FastAPI()
-
-
- @app.exception_handler(UnicornException)
- async def unicorn_exception_handler(request: Request, exc: UnicornException):
- return JSONResponse(
- status_code=418,
- content={"message": f"Oops! {exc.name} did something. There goes a rainbow..."},
- )
- ```
- """
-
- def decorator(func: DecoratedCallable) -> DecoratedCallable:
- self.add_exception_handler(exc_class_or_status_code, func)
- return func
-
- return decorator
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/background.py b/backend/.venv/lib/python3.12/site-packages/fastapi/background.py
deleted file mode 100644
index 20803ba..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/background.py
+++ /dev/null
@@ -1,60 +0,0 @@
-from typing import Annotated, Any, Callable
-
-from annotated_doc import Doc
-from starlette.background import BackgroundTasks as StarletteBackgroundTasks
-from typing_extensions import ParamSpec
-
-P = ParamSpec("P")
-
-
-class BackgroundTasks(StarletteBackgroundTasks):
- """
- A collection of background tasks that will be called after a response has been
- sent to the client.
-
- Read more about it in the
- [FastAPI docs for Background Tasks](https://fastapi.tiangolo.com/tutorial/background-tasks/).
-
- ## Example
-
- ```python
- from fastapi import BackgroundTasks, FastAPI
-
- app = FastAPI()
-
-
- def write_notification(email: str, message=""):
- with open("log.txt", mode="w") as email_file:
- content = f"notification for {email}: {message}"
- email_file.write(content)
-
-
- @app.post("/send-notification/{email}")
- async def send_notification(email: str, background_tasks: BackgroundTasks):
- background_tasks.add_task(write_notification, email, message="some notification")
- return {"message": "Notification sent in the background"}
- ```
- """
-
- def add_task(
- self,
- func: Annotated[
- Callable[P, Any],
- Doc(
- """
- The function to call after the response is sent.
-
- It can be a regular `def` function or an `async def` function.
- """
- ),
- ],
- *args: P.args,
- **kwargs: P.kwargs,
- ) -> None:
- """
- Add a function to be called in the background after the response is sent.
-
- Read more about it in the
- [FastAPI docs for Background Tasks](https://fastapi.tiangolo.com/tutorial/background-tasks/).
- """
- return super().add_task(func, *args, **kwargs)
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/cli.py b/backend/.venv/lib/python3.12/site-packages/fastapi/cli.py
deleted file mode 100644
index 8d3301e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/cli.py
+++ /dev/null
@@ -1,13 +0,0 @@
-try:
- from fastapi_cli.cli import main as cli_main
-
-except ImportError: # pragma: no cover
- cli_main = None # type: ignore
-
-
-def main() -> None:
- if not cli_main: # type: ignore[truthy-function]
- message = 'To use the fastapi command, please install "fastapi[standard]":\n\n\tpip install "fastapi[standard]"\n'
- print(message)
- raise RuntimeError(message) # noqa: B904
- cli_main()
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/concurrency.py b/backend/.venv/lib/python3.12/site-packages/fastapi/concurrency.py
deleted file mode 100644
index 76a5a2e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/concurrency.py
+++ /dev/null
@@ -1,41 +0,0 @@
-from collections.abc import AsyncGenerator
-from contextlib import AbstractContextManager
-from contextlib import asynccontextmanager as asynccontextmanager
-from typing import TypeVar
-
-import anyio.to_thread
-from anyio import CapacityLimiter
-from starlette.concurrency import iterate_in_threadpool as iterate_in_threadpool # noqa
-from starlette.concurrency import run_in_threadpool as run_in_threadpool # noqa
-from starlette.concurrency import ( # noqa
- run_until_first_complete as run_until_first_complete,
-)
-
-_T = TypeVar("_T")
-
-
-@asynccontextmanager
-async def contextmanager_in_threadpool(
- cm: AbstractContextManager[_T],
-) -> AsyncGenerator[_T, None]:
- # blocking __exit__ from running waiting on a free thread
- # can create race conditions/deadlocks if the context manager itself
- # has its own internal pool (e.g. a database connection pool)
- # to avoid this we let __exit__ run without a capacity limit
- # since we're creating a new limiter for each call, any non-zero limit
- # works (1 is arbitrary)
- exit_limiter = CapacityLimiter(1)
- try:
- yield await run_in_threadpool(cm.__enter__)
- except Exception as e:
- ok = bool(
- await anyio.to_thread.run_sync(
- cm.__exit__, type(e), e, e.__traceback__, limiter=exit_limiter
- )
- )
- if not ok:
- raise e
- else:
- await anyio.to_thread.run_sync(
- cm.__exit__, None, None, None, limiter=exit_limiter
- )
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/datastructures.py b/backend/.venv/lib/python3.12/site-packages/fastapi/datastructures.py
deleted file mode 100644
index 2bf5fdb..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/datastructures.py
+++ /dev/null
@@ -1,183 +0,0 @@
-from collections.abc import Mapping
-from typing import (
- Annotated,
- Any,
- BinaryIO,
- Callable,
- Optional,
- TypeVar,
- cast,
-)
-
-from annotated_doc import Doc
-from pydantic import GetJsonSchemaHandler
-from starlette.datastructures import URL as URL # noqa: F401
-from starlette.datastructures import Address as Address # noqa: F401
-from starlette.datastructures import FormData as FormData # noqa: F401
-from starlette.datastructures import Headers as Headers # noqa: F401
-from starlette.datastructures import QueryParams as QueryParams # noqa: F401
-from starlette.datastructures import State as State # noqa: F401
-from starlette.datastructures import UploadFile as StarletteUploadFile
-
-
-class UploadFile(StarletteUploadFile):
- """
- A file uploaded in a request.
-
- Define it as a *path operation function* (or dependency) parameter.
-
- If you are using a regular `def` function, you can use the `upload_file.file`
- attribute to access the raw standard Python file (blocking, not async), useful and
- needed for non-async code.
-
- Read more about it in the
- [FastAPI docs for Request Files](https://fastapi.tiangolo.com/tutorial/request-files/).
-
- ## Example
-
- ```python
- from typing import Annotated
-
- from fastapi import FastAPI, File, UploadFile
-
- app = FastAPI()
-
-
- @app.post("/files/")
- async def create_file(file: Annotated[bytes, File()]):
- return {"file_size": len(file)}
-
-
- @app.post("/uploadfile/")
- async def create_upload_file(file: UploadFile):
- return {"filename": file.filename}
- ```
- """
-
- file: Annotated[
- BinaryIO,
- Doc("The standard Python file object (non-async)."),
- ]
- filename: Annotated[Optional[str], Doc("The original file name.")]
- size: Annotated[Optional[int], Doc("The size of the file in bytes.")]
- headers: Annotated[Headers, Doc("The headers of the request.")]
- content_type: Annotated[
- Optional[str], Doc("The content type of the request, from the headers.")
- ]
-
- async def write(
- self,
- data: Annotated[
- bytes,
- Doc(
- """
- The bytes to write to the file.
- """
- ),
- ],
- ) -> None:
- """
- Write some bytes to the file.
-
- You normally wouldn't use this from a file you read in a request.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().write(data)
-
- async def read(
- self,
- size: Annotated[
- int,
- Doc(
- """
- The number of bytes to read from the file.
- """
- ),
- ] = -1,
- ) -> bytes:
- """
- Read some bytes from the file.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().read(size)
-
- async def seek(
- self,
- offset: Annotated[
- int,
- Doc(
- """
- The position in bytes to seek to in the file.
- """
- ),
- ],
- ) -> None:
- """
- Move to a position in the file.
-
- Any next read or write will be done from that position.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().seek(offset)
-
- async def close(self) -> None:
- """
- Close the file.
-
- To be awaitable, compatible with async, this is run in threadpool.
- """
- return await super().close()
-
- @classmethod
- def _validate(cls, __input_value: Any, _: Any) -> "UploadFile":
- if not isinstance(__input_value, StarletteUploadFile):
- raise ValueError(f"Expected UploadFile, received: {type(__input_value)}")
- return cast(UploadFile, __input_value)
-
- @classmethod
- def __get_pydantic_json_schema__(
- cls, core_schema: Mapping[str, Any], handler: GetJsonSchemaHandler
- ) -> dict[str, Any]:
- return {"type": "string", "format": "binary"}
-
- @classmethod
- def __get_pydantic_core_schema__(
- cls, source: type[Any], handler: Callable[[Any], Mapping[str, Any]]
- ) -> Mapping[str, Any]:
- from ._compat.v2 import with_info_plain_validator_function
-
- return with_info_plain_validator_function(cls._validate)
-
-
-class DefaultPlaceholder:
- """
- You shouldn't use this class directly.
-
- It's used internally to recognize when a default value has been overwritten, even
- if the overridden default value was truthy.
- """
-
- def __init__(self, value: Any):
- self.value = value
-
- def __bool__(self) -> bool:
- return bool(self.value)
-
- def __eq__(self, o: object) -> bool:
- return isinstance(o, DefaultPlaceholder) and o.value == self.value
-
-
-DefaultType = TypeVar("DefaultType")
-
-
-def Default(value: DefaultType) -> DefaultType:
- """
- You shouldn't use this function directly.
-
- It's used internally to recognize when a default value has been overwritten, even
- if the overridden default value was truthy.
- """
- return DefaultPlaceholder(value) # type: ignore
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__init__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index faeedf5..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/models.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/models.cpython-312.pyc
deleted file mode 100644
index fe421dd..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/models.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/utils.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/utils.cpython-312.pyc
deleted file mode 100644
index 9a0d464..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/__pycache__/utils.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/models.py b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/models.py
deleted file mode 100644
index 5839232..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/models.py
+++ /dev/null
@@ -1,193 +0,0 @@
-import inspect
-import sys
-from dataclasses import dataclass, field
-from functools import cached_property, partial
-from typing import Any, Callable, Optional, Union
-
-from fastapi._compat import ModelField
-from fastapi.security.base import SecurityBase
-from fastapi.types import DependencyCacheKey
-from typing_extensions import Literal
-
-if sys.version_info >= (3, 13): # pragma: no cover
- from inspect import iscoroutinefunction
-else: # pragma: no cover
- from asyncio import iscoroutinefunction
-
-
-def _unwrapped_call(call: Optional[Callable[..., Any]]) -> Any:
- if call is None:
- return call # pragma: no cover
- unwrapped = inspect.unwrap(_impartial(call))
- return unwrapped
-
-
-def _impartial(func: Callable[..., Any]) -> Callable[..., Any]:
- while isinstance(func, partial):
- func = func.func
- return func
-
-
-@dataclass
-class Dependant:
- path_params: list[ModelField] = field(default_factory=list)
- query_params: list[ModelField] = field(default_factory=list)
- header_params: list[ModelField] = field(default_factory=list)
- cookie_params: list[ModelField] = field(default_factory=list)
- body_params: list[ModelField] = field(default_factory=list)
- dependencies: list["Dependant"] = field(default_factory=list)
- name: Optional[str] = None
- call: Optional[Callable[..., Any]] = None
- request_param_name: Optional[str] = None
- websocket_param_name: Optional[str] = None
- http_connection_param_name: Optional[str] = None
- response_param_name: Optional[str] = None
- background_tasks_param_name: Optional[str] = None
- security_scopes_param_name: Optional[str] = None
- own_oauth_scopes: Optional[list[str]] = None
- parent_oauth_scopes: Optional[list[str]] = None
- use_cache: bool = True
- path: Optional[str] = None
- scope: Union[Literal["function", "request"], None] = None
-
- @cached_property
- def oauth_scopes(self) -> list[str]:
- scopes = self.parent_oauth_scopes.copy() if self.parent_oauth_scopes else []
- # This doesn't use a set to preserve order, just in case
- for scope in self.own_oauth_scopes or []:
- if scope not in scopes:
- scopes.append(scope)
- return scopes
-
- @cached_property
- def cache_key(self) -> DependencyCacheKey:
- scopes_for_cache = (
- tuple(sorted(set(self.oauth_scopes or []))) if self._uses_scopes else ()
- )
- return (
- self.call,
- scopes_for_cache,
- self.computed_scope or "",
- )
-
- @cached_property
- def _uses_scopes(self) -> bool:
- if self.own_oauth_scopes:
- return True
- if self.security_scopes_param_name is not None:
- return True
- if self._is_security_scheme:
- return True
- for sub_dep in self.dependencies:
- if sub_dep._uses_scopes:
- return True
- return False
-
- @cached_property
- def _is_security_scheme(self) -> bool:
- if self.call is None:
- return False # pragma: no cover
- unwrapped = _unwrapped_call(self.call)
- return isinstance(unwrapped, SecurityBase)
-
- # Mainly to get the type of SecurityBase, but it's the same self.call
- @cached_property
- def _security_scheme(self) -> SecurityBase:
- unwrapped = _unwrapped_call(self.call)
- assert isinstance(unwrapped, SecurityBase)
- return unwrapped
-
- @cached_property
- def _security_dependencies(self) -> list["Dependant"]:
- security_deps = [dep for dep in self.dependencies if dep._is_security_scheme]
- return security_deps
-
- @cached_property
- def is_gen_callable(self) -> bool:
- if self.call is None:
- return False # pragma: no cover
- if inspect.isgeneratorfunction(
- _impartial(self.call)
- ) or inspect.isgeneratorfunction(_unwrapped_call(self.call)):
- return True
- if inspect.isclass(_unwrapped_call(self.call)):
- return False
- dunder_call = getattr(_impartial(self.call), "__call__", None) # noqa: B004
- if dunder_call is None:
- return False # pragma: no cover
- if inspect.isgeneratorfunction(
- _impartial(dunder_call)
- ) or inspect.isgeneratorfunction(_unwrapped_call(dunder_call)):
- return True
- dunder_unwrapped_call = getattr(_unwrapped_call(self.call), "__call__", None) # noqa: B004
- if dunder_unwrapped_call is None:
- return False # pragma: no cover
- if inspect.isgeneratorfunction(
- _impartial(dunder_unwrapped_call)
- ) or inspect.isgeneratorfunction(_unwrapped_call(dunder_unwrapped_call)):
- return True
- return False
-
- @cached_property
- def is_async_gen_callable(self) -> bool:
- if self.call is None:
- return False # pragma: no cover
- if inspect.isasyncgenfunction(
- _impartial(self.call)
- ) or inspect.isasyncgenfunction(_unwrapped_call(self.call)):
- return True
- if inspect.isclass(_unwrapped_call(self.call)):
- return False
- dunder_call = getattr(_impartial(self.call), "__call__", None) # noqa: B004
- if dunder_call is None:
- return False # pragma: no cover
- if inspect.isasyncgenfunction(
- _impartial(dunder_call)
- ) or inspect.isasyncgenfunction(_unwrapped_call(dunder_call)):
- return True
- dunder_unwrapped_call = getattr(_unwrapped_call(self.call), "__call__", None) # noqa: B004
- if dunder_unwrapped_call is None:
- return False # pragma: no cover
- if inspect.isasyncgenfunction(
- _impartial(dunder_unwrapped_call)
- ) or inspect.isasyncgenfunction(_unwrapped_call(dunder_unwrapped_call)):
- return True
- return False
-
- @cached_property
- def is_coroutine_callable(self) -> bool:
- if self.call is None:
- return False # pragma: no cover
- if inspect.isroutine(_impartial(self.call)) and iscoroutinefunction(
- _impartial(self.call)
- ):
- return True
- if inspect.isroutine(_unwrapped_call(self.call)) and iscoroutinefunction(
- _unwrapped_call(self.call)
- ):
- return True
- if inspect.isclass(_unwrapped_call(self.call)):
- return False
- dunder_call = getattr(_impartial(self.call), "__call__", None) # noqa: B004
- if dunder_call is None:
- return False # pragma: no cover
- if iscoroutinefunction(_impartial(dunder_call)) or iscoroutinefunction(
- _unwrapped_call(dunder_call)
- ):
- return True
- dunder_unwrapped_call = getattr(_unwrapped_call(self.call), "__call__", None) # noqa: B004
- if dunder_unwrapped_call is None:
- return False # pragma: no cover
- if iscoroutinefunction(
- _impartial(dunder_unwrapped_call)
- ) or iscoroutinefunction(_unwrapped_call(dunder_unwrapped_call)):
- return True
- return False
-
- @cached_property
- def computed_scope(self) -> Union[str, None]:
- if self.scope:
- return self.scope
- if self.is_gen_callable or self.is_async_gen_callable:
- return "request"
- return None
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/utils.py b/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/utils.py
deleted file mode 100644
index 45e1ff3..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/dependencies/utils.py
+++ /dev/null
@@ -1,1021 +0,0 @@
-import dataclasses
-import inspect
-import sys
-from collections.abc import Coroutine, Mapping, Sequence
-from contextlib import AsyncExitStack, contextmanager
-from copy import copy, deepcopy
-from dataclasses import dataclass
-from typing import (
- Annotated,
- Any,
- Callable,
- ForwardRef,
- Optional,
- Union,
- cast,
-)
-
-import anyio
-from fastapi import params
-from fastapi._compat import (
- ModelField,
- RequiredParam,
- Undefined,
- _regenerate_error_with_loc,
- copy_field_info,
- create_body_model,
- evaluate_forwardref,
- field_annotation_is_scalar,
- get_cached_model_fields,
- get_missing_field_error,
- is_bytes_field,
- is_bytes_sequence_field,
- is_scalar_field,
- is_scalar_sequence_field,
- is_sequence_field,
- is_uploadfile_or_nonable_uploadfile_annotation,
- is_uploadfile_sequence_annotation,
- lenient_issubclass,
- sequence_types,
- serialize_sequence_value,
- value_is_sequence,
-)
-from fastapi.background import BackgroundTasks
-from fastapi.concurrency import (
- asynccontextmanager,
- contextmanager_in_threadpool,
-)
-from fastapi.dependencies.models import Dependant
-from fastapi.exceptions import DependencyScopeError
-from fastapi.logger import logger
-from fastapi.security.oauth2 import SecurityScopes
-from fastapi.types import DependencyCacheKey
-from fastapi.utils import create_model_field, get_path_param_names
-from pydantic import BaseModel
-from pydantic.fields import FieldInfo
-from starlette.background import BackgroundTasks as StarletteBackgroundTasks
-from starlette.concurrency import run_in_threadpool
-from starlette.datastructures import (
- FormData,
- Headers,
- ImmutableMultiDict,
- QueryParams,
- UploadFile,
-)
-from starlette.requests import HTTPConnection, Request
-from starlette.responses import Response
-from starlette.websockets import WebSocket
-from typing_extensions import Literal, get_args, get_origin
-
-multipart_not_installed_error = (
- 'Form data requires "python-multipart" to be installed. \n'
- 'You can install "python-multipart" with: \n\n'
- "pip install python-multipart\n"
-)
-multipart_incorrect_install_error = (
- 'Form data requires "python-multipart" to be installed. '
- 'It seems you installed "multipart" instead. \n'
- 'You can remove "multipart" with: \n\n'
- "pip uninstall multipart\n\n"
- 'And then install "python-multipart" with: \n\n'
- "pip install python-multipart\n"
-)
-
-
-def ensure_multipart_is_installed() -> None:
- try:
- from python_multipart import __version__
-
- # Import an attribute that can be mocked/deleted in testing
- assert __version__ > "0.0.12"
- except (ImportError, AssertionError):
- try:
- # __version__ is available in both multiparts, and can be mocked
- from multipart import __version__ # type: ignore[no-redef,import-untyped]
-
- assert __version__
- try:
- # parse_options_header is only available in the right multipart
- from multipart.multipart import ( # type: ignore[import-untyped]
- parse_options_header,
- )
-
- assert parse_options_header
- except ImportError:
- logger.error(multipart_incorrect_install_error)
- raise RuntimeError(multipart_incorrect_install_error) from None
- except ImportError:
- logger.error(multipart_not_installed_error)
- raise RuntimeError(multipart_not_installed_error) from None
-
-
-def get_parameterless_sub_dependant(*, depends: params.Depends, path: str) -> Dependant:
- assert callable(depends.dependency), (
- "A parameter-less dependency must have a callable dependency"
- )
- own_oauth_scopes: list[str] = []
- if isinstance(depends, params.Security) and depends.scopes:
- own_oauth_scopes.extend(depends.scopes)
- return get_dependant(
- path=path,
- call=depends.dependency,
- scope=depends.scope,
- own_oauth_scopes=own_oauth_scopes,
- )
-
-
-def get_flat_dependant(
- dependant: Dependant,
- *,
- skip_repeats: bool = False,
- visited: Optional[list[DependencyCacheKey]] = None,
- parent_oauth_scopes: Optional[list[str]] = None,
-) -> Dependant:
- if visited is None:
- visited = []
- visited.append(dependant.cache_key)
- use_parent_oauth_scopes = (parent_oauth_scopes or []) + (
- dependant.oauth_scopes or []
- )
-
- flat_dependant = Dependant(
- path_params=dependant.path_params.copy(),
- query_params=dependant.query_params.copy(),
- header_params=dependant.header_params.copy(),
- cookie_params=dependant.cookie_params.copy(),
- body_params=dependant.body_params.copy(),
- name=dependant.name,
- call=dependant.call,
- request_param_name=dependant.request_param_name,
- websocket_param_name=dependant.websocket_param_name,
- http_connection_param_name=dependant.http_connection_param_name,
- response_param_name=dependant.response_param_name,
- background_tasks_param_name=dependant.background_tasks_param_name,
- security_scopes_param_name=dependant.security_scopes_param_name,
- own_oauth_scopes=dependant.own_oauth_scopes,
- parent_oauth_scopes=use_parent_oauth_scopes,
- use_cache=dependant.use_cache,
- path=dependant.path,
- scope=dependant.scope,
- )
- for sub_dependant in dependant.dependencies:
- if skip_repeats and sub_dependant.cache_key in visited:
- continue
- flat_sub = get_flat_dependant(
- sub_dependant,
- skip_repeats=skip_repeats,
- visited=visited,
- parent_oauth_scopes=flat_dependant.oauth_scopes,
- )
- flat_dependant.dependencies.append(flat_sub)
- flat_dependant.path_params.extend(flat_sub.path_params)
- flat_dependant.query_params.extend(flat_sub.query_params)
- flat_dependant.header_params.extend(flat_sub.header_params)
- flat_dependant.cookie_params.extend(flat_sub.cookie_params)
- flat_dependant.body_params.extend(flat_sub.body_params)
- flat_dependant.dependencies.extend(flat_sub.dependencies)
-
- return flat_dependant
-
-
-def _get_flat_fields_from_params(fields: list[ModelField]) -> list[ModelField]:
- if not fields:
- return fields
- first_field = fields[0]
- if len(fields) == 1 and lenient_issubclass(first_field.type_, BaseModel):
- fields_to_extract = get_cached_model_fields(first_field.type_)
- return fields_to_extract
- return fields
-
-
-def get_flat_params(dependant: Dependant) -> list[ModelField]:
- flat_dependant = get_flat_dependant(dependant, skip_repeats=True)
- path_params = _get_flat_fields_from_params(flat_dependant.path_params)
- query_params = _get_flat_fields_from_params(flat_dependant.query_params)
- header_params = _get_flat_fields_from_params(flat_dependant.header_params)
- cookie_params = _get_flat_fields_from_params(flat_dependant.cookie_params)
- return path_params + query_params + header_params + cookie_params
-
-
-def _get_signature(call: Callable[..., Any]) -> inspect.Signature:
- if sys.version_info >= (3, 10):
- try:
- signature = inspect.signature(call, eval_str=True)
- except NameError:
- # Handle type annotations with if TYPE_CHECKING, not used by FastAPI
- # e.g. dependency return types
- signature = inspect.signature(call)
- else:
- signature = inspect.signature(call)
- return signature
-
-
-def get_typed_signature(call: Callable[..., Any]) -> inspect.Signature:
- signature = _get_signature(call)
- unwrapped = inspect.unwrap(call)
- globalns = getattr(unwrapped, "__globals__", {})
- typed_params = [
- inspect.Parameter(
- name=param.name,
- kind=param.kind,
- default=param.default,
- annotation=get_typed_annotation(param.annotation, globalns),
- )
- for param in signature.parameters.values()
- ]
- typed_signature = inspect.Signature(typed_params)
- return typed_signature
-
-
-def get_typed_annotation(annotation: Any, globalns: dict[str, Any]) -> Any:
- if isinstance(annotation, str):
- annotation = ForwardRef(annotation)
- annotation = evaluate_forwardref(annotation, globalns, globalns)
- if annotation is type(None):
- return None
- return annotation
-
-
-def get_typed_return_annotation(call: Callable[..., Any]) -> Any:
- signature = _get_signature(call)
- unwrapped = inspect.unwrap(call)
- annotation = signature.return_annotation
-
- if annotation is inspect.Signature.empty:
- return None
-
- globalns = getattr(unwrapped, "__globals__", {})
- return get_typed_annotation(annotation, globalns)
-
-
-def get_dependant(
- *,
- path: str,
- call: Callable[..., Any],
- name: Optional[str] = None,
- own_oauth_scopes: Optional[list[str]] = None,
- parent_oauth_scopes: Optional[list[str]] = None,
- use_cache: bool = True,
- scope: Union[Literal["function", "request"], None] = None,
-) -> Dependant:
- dependant = Dependant(
- call=call,
- name=name,
- path=path,
- use_cache=use_cache,
- scope=scope,
- own_oauth_scopes=own_oauth_scopes,
- parent_oauth_scopes=parent_oauth_scopes,
- )
- current_scopes = (parent_oauth_scopes or []) + (own_oauth_scopes or [])
- path_param_names = get_path_param_names(path)
- endpoint_signature = get_typed_signature(call)
- signature_params = endpoint_signature.parameters
- for param_name, param in signature_params.items():
- is_path_param = param_name in path_param_names
- param_details = analyze_param(
- param_name=param_name,
- annotation=param.annotation,
- value=param.default,
- is_path_param=is_path_param,
- )
- if param_details.depends is not None:
- assert param_details.depends.dependency
- if (
- (dependant.is_gen_callable or dependant.is_async_gen_callable)
- and dependant.computed_scope == "request"
- and param_details.depends.scope == "function"
- ):
- assert dependant.call
- raise DependencyScopeError(
- f'The dependency "{dependant.call.__name__}" has a scope of '
- '"request", it cannot depend on dependencies with scope "function".'
- )
- sub_own_oauth_scopes: list[str] = []
- if isinstance(param_details.depends, params.Security):
- if param_details.depends.scopes:
- sub_own_oauth_scopes = list(param_details.depends.scopes)
- sub_dependant = get_dependant(
- path=path,
- call=param_details.depends.dependency,
- name=param_name,
- own_oauth_scopes=sub_own_oauth_scopes,
- parent_oauth_scopes=current_scopes,
- use_cache=param_details.depends.use_cache,
- scope=param_details.depends.scope,
- )
- dependant.dependencies.append(sub_dependant)
- continue
- if add_non_field_param_to_dependency(
- param_name=param_name,
- type_annotation=param_details.type_annotation,
- dependant=dependant,
- ):
- assert param_details.field is None, (
- f"Cannot specify multiple FastAPI annotations for {param_name!r}"
- )
- continue
- assert param_details.field is not None
- if isinstance(param_details.field.field_info, params.Body):
- dependant.body_params.append(param_details.field)
- else:
- add_param_to_fields(field=param_details.field, dependant=dependant)
- return dependant
-
-
-def add_non_field_param_to_dependency(
- *, param_name: str, type_annotation: Any, dependant: Dependant
-) -> Optional[bool]:
- if lenient_issubclass(type_annotation, Request):
- dependant.request_param_name = param_name
- return True
- elif lenient_issubclass(type_annotation, WebSocket):
- dependant.websocket_param_name = param_name
- return True
- elif lenient_issubclass(type_annotation, HTTPConnection):
- dependant.http_connection_param_name = param_name
- return True
- elif lenient_issubclass(type_annotation, Response):
- dependant.response_param_name = param_name
- return True
- elif lenient_issubclass(type_annotation, StarletteBackgroundTasks):
- dependant.background_tasks_param_name = param_name
- return True
- elif lenient_issubclass(type_annotation, SecurityScopes):
- dependant.security_scopes_param_name = param_name
- return True
- return None
-
-
-@dataclass
-class ParamDetails:
- type_annotation: Any
- depends: Optional[params.Depends]
- field: Optional[ModelField]
-
-
-def analyze_param(
- *,
- param_name: str,
- annotation: Any,
- value: Any,
- is_path_param: bool,
-) -> ParamDetails:
- field_info = None
- depends = None
- type_annotation: Any = Any
- use_annotation: Any = Any
- if annotation is not inspect.Signature.empty:
- use_annotation = annotation
- type_annotation = annotation
- # Extract Annotated info
- if get_origin(use_annotation) is Annotated:
- annotated_args = get_args(annotation)
- type_annotation = annotated_args[0]
- fastapi_annotations = [
- arg
- for arg in annotated_args[1:]
- if isinstance(arg, (FieldInfo, params.Depends))
- ]
- fastapi_specific_annotations = [
- arg
- for arg in fastapi_annotations
- if isinstance(
- arg,
- (
- params.Param,
- params.Body,
- params.Depends,
- ),
- )
- ]
- if fastapi_specific_annotations:
- fastapi_annotation: Union[FieldInfo, params.Depends, None] = (
- fastapi_specific_annotations[-1]
- )
- else:
- fastapi_annotation = None
- # Set default for Annotated FieldInfo
- if isinstance(fastapi_annotation, FieldInfo):
- # Copy `field_info` because we mutate `field_info.default` below.
- field_info = copy_field_info(
- field_info=fastapi_annotation, # type: ignore[arg-type]
- annotation=use_annotation,
- )
- assert (
- field_info.default == Undefined or field_info.default == RequiredParam
- ), (
- f"`{field_info.__class__.__name__}` default value cannot be set in"
- f" `Annotated` for {param_name!r}. Set the default value with `=` instead."
- )
- if value is not inspect.Signature.empty:
- assert not is_path_param, "Path parameters cannot have default values"
- field_info.default = value
- else:
- field_info.default = RequiredParam
- # Get Annotated Depends
- elif isinstance(fastapi_annotation, params.Depends):
- depends = fastapi_annotation
- # Get Depends from default value
- if isinstance(value, params.Depends):
- assert depends is None, (
- "Cannot specify `Depends` in `Annotated` and default value"
- f" together for {param_name!r}"
- )
- assert field_info is None, (
- "Cannot specify a FastAPI annotation in `Annotated` and `Depends` as a"
- f" default value together for {param_name!r}"
- )
- depends = value
- # Get FieldInfo from default value
- elif isinstance(value, FieldInfo):
- assert field_info is None, (
- "Cannot specify FastAPI annotations in `Annotated` and default value"
- f" together for {param_name!r}"
- )
- field_info = value # type: ignore[assignment]
- if isinstance(field_info, FieldInfo):
- field_info.annotation = type_annotation
-
- # Get Depends from type annotation
- if depends is not None and depends.dependency is None:
- # Copy `depends` before mutating it
- depends = copy(depends)
- depends = dataclasses.replace(depends, dependency=type_annotation)
-
- # Handle non-param type annotations like Request
- if lenient_issubclass(
- type_annotation,
- (
- Request,
- WebSocket,
- HTTPConnection,
- Response,
- StarletteBackgroundTasks,
- SecurityScopes,
- ),
- ):
- assert depends is None, f"Cannot specify `Depends` for type {type_annotation!r}"
- assert field_info is None, (
- f"Cannot specify FastAPI annotation for type {type_annotation!r}"
- )
- # Handle default assignations, neither field_info nor depends was not found in Annotated nor default value
- elif field_info is None and depends is None:
- default_value = value if value is not inspect.Signature.empty else RequiredParam
- if is_path_param:
- # We might check here that `default_value is RequiredParam`, but the fact is that the same
- # parameter might sometimes be a path parameter and sometimes not. See
- # `tests/test_infer_param_optionality.py` for an example.
- field_info = params.Path(annotation=use_annotation)
- elif is_uploadfile_or_nonable_uploadfile_annotation(
- type_annotation
- ) or is_uploadfile_sequence_annotation(type_annotation):
- field_info = params.File(annotation=use_annotation, default=default_value)
- elif not field_annotation_is_scalar(annotation=type_annotation):
- field_info = params.Body(annotation=use_annotation, default=default_value)
- else:
- field_info = params.Query(annotation=use_annotation, default=default_value)
-
- field = None
- # It's a field_info, not a dependency
- if field_info is not None:
- # Handle field_info.in_
- if is_path_param:
- assert isinstance(field_info, params.Path), (
- f"Cannot use `{field_info.__class__.__name__}` for path param"
- f" {param_name!r}"
- )
- elif (
- isinstance(field_info, params.Param)
- and getattr(field_info, "in_", None) is None
- ):
- field_info.in_ = params.ParamTypes.query
- use_annotation_from_field_info = use_annotation
- if isinstance(field_info, params.Form):
- ensure_multipart_is_installed()
- if not field_info.alias and getattr(field_info, "convert_underscores", None):
- alias = param_name.replace("_", "-")
- else:
- alias = field_info.alias or param_name
- field_info.alias = alias
- field = create_model_field(
- name=param_name,
- type_=use_annotation_from_field_info,
- default=field_info.default,
- alias=alias,
- required=field_info.default in (RequiredParam, Undefined),
- field_info=field_info,
- )
- if is_path_param:
- assert is_scalar_field(field=field), (
- "Path params must be of one of the supported types"
- )
- elif isinstance(field_info, params.Query):
- assert (
- is_scalar_field(field)
- or is_scalar_sequence_field(field)
- or (
- lenient_issubclass(field.type_, BaseModel)
- # For Pydantic v1
- and getattr(field, "shape", 1) == 1
- )
- )
-
- return ParamDetails(type_annotation=type_annotation, depends=depends, field=field)
-
-
-def add_param_to_fields(*, field: ModelField, dependant: Dependant) -> None:
- field_info = field.field_info
- field_info_in = getattr(field_info, "in_", None)
- if field_info_in == params.ParamTypes.path:
- dependant.path_params.append(field)
- elif field_info_in == params.ParamTypes.query:
- dependant.query_params.append(field)
- elif field_info_in == params.ParamTypes.header:
- dependant.header_params.append(field)
- else:
- assert field_info_in == params.ParamTypes.cookie, (
- f"non-body parameters must be in path, query, header or cookie: {field.name}"
- )
- dependant.cookie_params.append(field)
-
-
-async def _solve_generator(
- *, dependant: Dependant, stack: AsyncExitStack, sub_values: dict[str, Any]
-) -> Any:
- assert dependant.call
- if dependant.is_async_gen_callable:
- cm = asynccontextmanager(dependant.call)(**sub_values)
- elif dependant.is_gen_callable:
- cm = contextmanager_in_threadpool(contextmanager(dependant.call)(**sub_values))
- return await stack.enter_async_context(cm)
-
-
-@dataclass
-class SolvedDependency:
- values: dict[str, Any]
- errors: list[Any]
- background_tasks: Optional[StarletteBackgroundTasks]
- response: Response
- dependency_cache: dict[DependencyCacheKey, Any]
-
-
-async def solve_dependencies(
- *,
- request: Union[Request, WebSocket],
- dependant: Dependant,
- body: Optional[Union[dict[str, Any], FormData]] = None,
- background_tasks: Optional[StarletteBackgroundTasks] = None,
- response: Optional[Response] = None,
- dependency_overrides_provider: Optional[Any] = None,
- dependency_cache: Optional[dict[DependencyCacheKey, Any]] = None,
- # TODO: remove this parameter later, no longer used, not removing it yet as some
- # people might be monkey patching this function (although that's not supported)
- async_exit_stack: AsyncExitStack,
- embed_body_fields: bool,
-) -> SolvedDependency:
- request_astack = request.scope.get("fastapi_inner_astack")
- assert isinstance(request_astack, AsyncExitStack), (
- "fastapi_inner_astack not found in request scope"
- )
- function_astack = request.scope.get("fastapi_function_astack")
- assert isinstance(function_astack, AsyncExitStack), (
- "fastapi_function_astack not found in request scope"
- )
- values: dict[str, Any] = {}
- errors: list[Any] = []
- if response is None:
- response = Response()
- del response.headers["content-length"]
- response.status_code = None # type: ignore
- if dependency_cache is None:
- dependency_cache = {}
- for sub_dependant in dependant.dependencies:
- sub_dependant.call = cast(Callable[..., Any], sub_dependant.call)
- call = sub_dependant.call
- use_sub_dependant = sub_dependant
- if (
- dependency_overrides_provider
- and dependency_overrides_provider.dependency_overrides
- ):
- original_call = sub_dependant.call
- call = getattr(
- dependency_overrides_provider, "dependency_overrides", {}
- ).get(original_call, original_call)
- use_path: str = sub_dependant.path # type: ignore
- use_sub_dependant = get_dependant(
- path=use_path,
- call=call,
- name=sub_dependant.name,
- parent_oauth_scopes=sub_dependant.oauth_scopes,
- scope=sub_dependant.scope,
- )
-
- solved_result = await solve_dependencies(
- request=request,
- dependant=use_sub_dependant,
- body=body,
- background_tasks=background_tasks,
- response=response,
- dependency_overrides_provider=dependency_overrides_provider,
- dependency_cache=dependency_cache,
- async_exit_stack=async_exit_stack,
- embed_body_fields=embed_body_fields,
- )
- background_tasks = solved_result.background_tasks
- if solved_result.errors:
- errors.extend(solved_result.errors)
- continue
- if sub_dependant.use_cache and sub_dependant.cache_key in dependency_cache:
- solved = dependency_cache[sub_dependant.cache_key]
- elif (
- use_sub_dependant.is_gen_callable or use_sub_dependant.is_async_gen_callable
- ):
- use_astack = request_astack
- if sub_dependant.scope == "function":
- use_astack = function_astack
- solved = await _solve_generator(
- dependant=use_sub_dependant,
- stack=use_astack,
- sub_values=solved_result.values,
- )
- elif use_sub_dependant.is_coroutine_callable:
- solved = await call(**solved_result.values)
- else:
- solved = await run_in_threadpool(call, **solved_result.values)
- if sub_dependant.name is not None:
- values[sub_dependant.name] = solved
- if sub_dependant.cache_key not in dependency_cache:
- dependency_cache[sub_dependant.cache_key] = solved
- path_values, path_errors = request_params_to_args(
- dependant.path_params, request.path_params
- )
- query_values, query_errors = request_params_to_args(
- dependant.query_params, request.query_params
- )
- header_values, header_errors = request_params_to_args(
- dependant.header_params, request.headers
- )
- cookie_values, cookie_errors = request_params_to_args(
- dependant.cookie_params, request.cookies
- )
- values.update(path_values)
- values.update(query_values)
- values.update(header_values)
- values.update(cookie_values)
- errors += path_errors + query_errors + header_errors + cookie_errors
- if dependant.body_params:
- (
- body_values,
- body_errors,
- ) = await request_body_to_args( # body_params checked above
- body_fields=dependant.body_params,
- received_body=body,
- embed_body_fields=embed_body_fields,
- )
- values.update(body_values)
- errors.extend(body_errors)
- if dependant.http_connection_param_name:
- values[dependant.http_connection_param_name] = request
- if dependant.request_param_name and isinstance(request, Request):
- values[dependant.request_param_name] = request
- elif dependant.websocket_param_name and isinstance(request, WebSocket):
- values[dependant.websocket_param_name] = request
- if dependant.background_tasks_param_name:
- if background_tasks is None:
- background_tasks = BackgroundTasks()
- values[dependant.background_tasks_param_name] = background_tasks
- if dependant.response_param_name:
- values[dependant.response_param_name] = response
- if dependant.security_scopes_param_name:
- values[dependant.security_scopes_param_name] = SecurityScopes(
- scopes=dependant.oauth_scopes
- )
- return SolvedDependency(
- values=values,
- errors=errors,
- background_tasks=background_tasks,
- response=response,
- dependency_cache=dependency_cache,
- )
-
-
-def _validate_value_with_model_field(
- *, field: ModelField, value: Any, values: dict[str, Any], loc: tuple[str, ...]
-) -> tuple[Any, list[Any]]:
- if value is None:
- if field.required:
- return None, [get_missing_field_error(loc=loc)]
- else:
- return deepcopy(field.default), []
- v_, errors_ = field.validate(value, values, loc=loc)
- if isinstance(errors_, list):
- new_errors = _regenerate_error_with_loc(errors=errors_, loc_prefix=())
- return None, new_errors
- else:
- return v_, []
-
-
-def _get_multidict_value(
- field: ModelField, values: Mapping[str, Any], alias: Union[str, None] = None
-) -> Any:
- alias = alias or get_validation_alias(field)
- if is_sequence_field(field) and isinstance(values, (ImmutableMultiDict, Headers)):
- value = values.getlist(alias)
- else:
- value = values.get(alias, None)
- if (
- value is None
- or (
- isinstance(field.field_info, params.Form)
- and isinstance(value, str) # For type checks
- and value == ""
- )
- or (is_sequence_field(field) and len(value) == 0)
- ):
- if field.required:
- return
- else:
- return deepcopy(field.default)
- return value
-
-
-def request_params_to_args(
- fields: Sequence[ModelField],
- received_params: Union[Mapping[str, Any], QueryParams, Headers],
-) -> tuple[dict[str, Any], list[Any]]:
- values: dict[str, Any] = {}
- errors: list[dict[str, Any]] = []
-
- if not fields:
- return values, errors
-
- first_field = fields[0]
- fields_to_extract = fields
- single_not_embedded_field = False
- default_convert_underscores = True
- if len(fields) == 1 and lenient_issubclass(first_field.type_, BaseModel):
- fields_to_extract = get_cached_model_fields(first_field.type_)
- single_not_embedded_field = True
- # If headers are in a Pydantic model, the way to disable convert_underscores
- # would be with Header(convert_underscores=False) at the Pydantic model level
- default_convert_underscores = getattr(
- first_field.field_info, "convert_underscores", True
- )
-
- params_to_process: dict[str, Any] = {}
-
- processed_keys = set()
-
- for field in fields_to_extract:
- alias = None
- if isinstance(received_params, Headers):
- # Handle fields extracted from a Pydantic Model for a header, each field
- # doesn't have a FieldInfo of type Header with the default convert_underscores=True
- convert_underscores = getattr(
- field.field_info, "convert_underscores", default_convert_underscores
- )
- if convert_underscores:
- alias = get_validation_alias(field)
- if alias == field.name:
- alias = alias.replace("_", "-")
- value = _get_multidict_value(field, received_params, alias=alias)
- if value is not None:
- params_to_process[get_validation_alias(field)] = value
- processed_keys.add(alias or get_validation_alias(field))
-
- for key in received_params.keys():
- if key not in processed_keys:
- if hasattr(received_params, "getlist"):
- value = received_params.getlist(key)
- if isinstance(value, list) and (len(value) == 1):
- params_to_process[key] = value[0]
- else:
- params_to_process[key] = value
- else:
- params_to_process[key] = received_params.get(key)
-
- if single_not_embedded_field:
- field_info = first_field.field_info
- assert isinstance(field_info, params.Param), (
- "Params must be subclasses of Param"
- )
- loc: tuple[str, ...] = (field_info.in_.value,)
- v_, errors_ = _validate_value_with_model_field(
- field=first_field, value=params_to_process, values=values, loc=loc
- )
- return {first_field.name: v_}, errors_
-
- for field in fields:
- value = _get_multidict_value(field, received_params)
- field_info = field.field_info
- assert isinstance(field_info, params.Param), (
- "Params must be subclasses of Param"
- )
- loc = (field_info.in_.value, get_validation_alias(field))
- v_, errors_ = _validate_value_with_model_field(
- field=field, value=value, values=values, loc=loc
- )
- if errors_:
- errors.extend(errors_)
- else:
- values[field.name] = v_
- return values, errors
-
-
-def is_union_of_base_models(field_type: Any) -> bool:
- """Check if field type is a Union where all members are BaseModel subclasses."""
- from fastapi.types import UnionType
-
- origin = get_origin(field_type)
-
- # Check if it's a Union type (covers both typing.Union and types.UnionType in Python 3.10+)
- if origin is not Union and origin is not UnionType:
- return False
-
- union_args = get_args(field_type)
-
- for arg in union_args:
- if not lenient_issubclass(arg, BaseModel):
- return False
-
- return True
-
-
-def _should_embed_body_fields(fields: list[ModelField]) -> bool:
- if not fields:
- return False
- # More than one dependency could have the same field, it would show up as multiple
- # fields but it's the same one, so count them by name
- body_param_names_set = {field.name for field in fields}
- # A top level field has to be a single field, not multiple
- if len(body_param_names_set) > 1:
- return True
- first_field = fields[0]
- # If it explicitly specifies it is embedded, it has to be embedded
- if getattr(first_field.field_info, "embed", None):
- return True
- # If it's a Form (or File) field, it has to be a BaseModel (or a union of BaseModels) to be top level
- # otherwise it has to be embedded, so that the key value pair can be extracted
- if (
- isinstance(first_field.field_info, params.Form)
- and not lenient_issubclass(first_field.type_, BaseModel)
- and not is_union_of_base_models(first_field.type_)
- ):
- return True
- return False
-
-
-async def _extract_form_body(
- body_fields: list[ModelField],
- received_body: FormData,
-) -> dict[str, Any]:
- values = {}
-
- for field in body_fields:
- value = _get_multidict_value(field, received_body)
- field_info = field.field_info
- if (
- isinstance(field_info, params.File)
- and is_bytes_field(field)
- and isinstance(value, UploadFile)
- ):
- value = await value.read()
- elif (
- is_bytes_sequence_field(field)
- and isinstance(field_info, params.File)
- and value_is_sequence(value)
- ):
- # For types
- assert isinstance(value, sequence_types)
- results: list[Union[bytes, str]] = []
-
- async def process_fn(
- fn: Callable[[], Coroutine[Any, Any, Any]],
- ) -> None:
- result = await fn()
- results.append(result) # noqa: B023
-
- async with anyio.create_task_group() as tg:
- for sub_value in value:
- tg.start_soon(process_fn, sub_value.read)
- value = serialize_sequence_value(field=field, value=results)
- if value is not None:
- values[get_validation_alias(field)] = value
- field_aliases = {get_validation_alias(field) for field in body_fields}
- for key in received_body.keys():
- if key not in field_aliases:
- param_values = received_body.getlist(key)
- if len(param_values) == 1:
- values[key] = param_values[0]
- else:
- values[key] = param_values
- return values
-
-
-async def request_body_to_args(
- body_fields: list[ModelField],
- received_body: Optional[Union[dict[str, Any], FormData]],
- embed_body_fields: bool,
-) -> tuple[dict[str, Any], list[dict[str, Any]]]:
- values: dict[str, Any] = {}
- errors: list[dict[str, Any]] = []
- assert body_fields, "request_body_to_args() should be called with fields"
- single_not_embedded_field = len(body_fields) == 1 and not embed_body_fields
- first_field = body_fields[0]
- body_to_process = received_body
-
- fields_to_extract: list[ModelField] = body_fields
-
- if (
- single_not_embedded_field
- and lenient_issubclass(first_field.type_, BaseModel)
- and isinstance(received_body, FormData)
- ):
- fields_to_extract = get_cached_model_fields(first_field.type_)
-
- if isinstance(received_body, FormData):
- body_to_process = await _extract_form_body(fields_to_extract, received_body)
-
- if single_not_embedded_field:
- loc: tuple[str, ...] = ("body",)
- v_, errors_ = _validate_value_with_model_field(
- field=first_field, value=body_to_process, values=values, loc=loc
- )
- return {first_field.name: v_}, errors_
- for field in body_fields:
- loc = ("body", get_validation_alias(field))
- value: Optional[Any] = None
- if body_to_process is not None:
- try:
- value = body_to_process.get(get_validation_alias(field))
- # If the received body is a list, not a dict
- except AttributeError:
- errors.append(get_missing_field_error(loc))
- continue
- v_, errors_ = _validate_value_with_model_field(
- field=field, value=value, values=values, loc=loc
- )
- if errors_:
- errors.extend(errors_)
- else:
- values[field.name] = v_
- return values, errors
-
-
-def get_body_field(
- *, flat_dependant: Dependant, name: str, embed_body_fields: bool
-) -> Optional[ModelField]:
- """
- Get a ModelField representing the request body for a path operation, combining
- all body parameters into a single field if necessary.
-
- Used to check if it's form data (with `isinstance(body_field, params.Form)`)
- or JSON and to generate the JSON Schema for a request body.
-
- This is **not** used to validate/parse the request body, that's done with each
- individual body parameter.
- """
- if not flat_dependant.body_params:
- return None
- first_param = flat_dependant.body_params[0]
- if not embed_body_fields:
- return first_param
- model_name = "Body_" + name
- BodyModel = create_body_model(
- fields=flat_dependant.body_params, model_name=model_name
- )
- required = any(True for f in flat_dependant.body_params if f.required)
- BodyFieldInfo_kwargs: dict[str, Any] = {
- "annotation": BodyModel,
- "alias": "body",
- }
- if not required:
- BodyFieldInfo_kwargs["default"] = None
- if any(isinstance(f.field_info, params.File) for f in flat_dependant.body_params):
- BodyFieldInfo: type[params.Body] = params.File
- elif any(isinstance(f.field_info, params.Form) for f in flat_dependant.body_params):
- BodyFieldInfo = params.Form
- else:
- BodyFieldInfo = params.Body
-
- body_param_media_types = [
- f.field_info.media_type
- for f in flat_dependant.body_params
- if isinstance(f.field_info, params.Body)
- ]
- if len(set(body_param_media_types)) == 1:
- BodyFieldInfo_kwargs["media_type"] = body_param_media_types[0]
- final_field = create_model_field(
- name="body",
- type_=BodyModel,
- required=required,
- alias="body",
- field_info=BodyFieldInfo(**BodyFieldInfo_kwargs),
- )
- return final_field
-
-
-def get_validation_alias(field: ModelField) -> str:
- va = getattr(field, "validation_alias", None)
- return va or field.alias
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/encoders.py b/backend/.venv/lib/python3.12/site-packages/fastapi/encoders.py
deleted file mode 100644
index e8610c9..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/encoders.py
+++ /dev/null
@@ -1,346 +0,0 @@
-import dataclasses
-import datetime
-from collections import defaultdict, deque
-from decimal import Decimal
-from enum import Enum
-from ipaddress import (
- IPv4Address,
- IPv4Interface,
- IPv4Network,
- IPv6Address,
- IPv6Interface,
- IPv6Network,
-)
-from pathlib import Path, PurePath
-from re import Pattern
-from types import GeneratorType
-from typing import Annotated, Any, Callable, Optional, Union
-from uuid import UUID
-
-from annotated_doc import Doc
-from fastapi.exceptions import PydanticV1NotSupportedError
-from fastapi.types import IncEx
-from pydantic import BaseModel
-from pydantic.color import Color
-from pydantic.networks import AnyUrl, NameEmail
-from pydantic.types import SecretBytes, SecretStr
-from pydantic_core import PydanticUndefinedType
-
-from ._compat import (
- Url,
- is_pydantic_v1_model_instance,
-)
-
-
-# Taken from Pydantic v1 as is
-def isoformat(o: Union[datetime.date, datetime.time]) -> str:
- return o.isoformat()
-
-
-# Adapted from Pydantic v1
-# TODO: pv2 should this return strings instead?
-def decimal_encoder(dec_value: Decimal) -> Union[int, float]:
- """
- Encodes a Decimal as int if there's no exponent, otherwise float
-
- This is useful when we use ConstrainedDecimal to represent Numeric(x,0)
- where an integer (but not int typed) is used. Encoding this as a float
- results in failed round-tripping between encode and parse.
- Our Id type is a prime example of this.
-
- >>> decimal_encoder(Decimal("1.0"))
- 1.0
-
- >>> decimal_encoder(Decimal("1"))
- 1
-
- >>> decimal_encoder(Decimal("NaN"))
- nan
- """
- exponent = dec_value.as_tuple().exponent
- if isinstance(exponent, int) and exponent >= 0:
- return int(dec_value)
- else:
- return float(dec_value)
-
-
-ENCODERS_BY_TYPE: dict[type[Any], Callable[[Any], Any]] = {
- bytes: lambda o: o.decode(),
- Color: str,
- datetime.date: isoformat,
- datetime.datetime: isoformat,
- datetime.time: isoformat,
- datetime.timedelta: lambda td: td.total_seconds(),
- Decimal: decimal_encoder,
- Enum: lambda o: o.value,
- frozenset: list,
- deque: list,
- GeneratorType: list,
- IPv4Address: str,
- IPv4Interface: str,
- IPv4Network: str,
- IPv6Address: str,
- IPv6Interface: str,
- IPv6Network: str,
- NameEmail: str,
- Path: str,
- Pattern: lambda o: o.pattern,
- SecretBytes: str,
- SecretStr: str,
- set: list,
- UUID: str,
- Url: str,
- AnyUrl: str,
-}
-
-
-def generate_encoders_by_class_tuples(
- type_encoder_map: dict[Any, Callable[[Any], Any]],
-) -> dict[Callable[[Any], Any], tuple[Any, ...]]:
- encoders_by_class_tuples: dict[Callable[[Any], Any], tuple[Any, ...]] = defaultdict(
- tuple
- )
- for type_, encoder in type_encoder_map.items():
- encoders_by_class_tuples[encoder] += (type_,)
- return encoders_by_class_tuples
-
-
-encoders_by_class_tuples = generate_encoders_by_class_tuples(ENCODERS_BY_TYPE)
-
-
-def jsonable_encoder(
- obj: Annotated[
- Any,
- Doc(
- """
- The input object to convert to JSON.
- """
- ),
- ],
- include: Annotated[
- Optional[IncEx],
- Doc(
- """
- Pydantic's `include` parameter, passed to Pydantic models to set the
- fields to include.
- """
- ),
- ] = None,
- exclude: Annotated[
- Optional[IncEx],
- Doc(
- """
- Pydantic's `exclude` parameter, passed to Pydantic models to set the
- fields to exclude.
- """
- ),
- ] = None,
- by_alias: Annotated[
- bool,
- Doc(
- """
- Pydantic's `by_alias` parameter, passed to Pydantic models to define if
- the output should use the alias names (when provided) or the Python
- attribute names. In an API, if you set an alias, it's probably because you
- want to use it in the result, so you probably want to leave this set to
- `True`.
- """
- ),
- ] = True,
- exclude_unset: Annotated[
- bool,
- Doc(
- """
- Pydantic's `exclude_unset` parameter, passed to Pydantic models to define
- if it should exclude from the output the fields that were not explicitly
- set (and that only had their default values).
- """
- ),
- ] = False,
- exclude_defaults: Annotated[
- bool,
- Doc(
- """
- Pydantic's `exclude_defaults` parameter, passed to Pydantic models to define
- if it should exclude from the output the fields that had the same default
- value, even when they were explicitly set.
- """
- ),
- ] = False,
- exclude_none: Annotated[
- bool,
- Doc(
- """
- Pydantic's `exclude_none` parameter, passed to Pydantic models to define
- if it should exclude from the output any fields that have a `None` value.
- """
- ),
- ] = False,
- custom_encoder: Annotated[
- Optional[dict[Any, Callable[[Any], Any]]],
- Doc(
- """
- Pydantic's `custom_encoder` parameter, passed to Pydantic models to define
- a custom encoder.
- """
- ),
- ] = None,
- sqlalchemy_safe: Annotated[
- bool,
- Doc(
- """
- Exclude from the output any fields that start with the name `_sa`.
-
- This is mainly a hack for compatibility with SQLAlchemy objects, they
- store internal SQLAlchemy-specific state in attributes named with `_sa`,
- and those objects can't (and shouldn't be) serialized to JSON.
- """
- ),
- ] = True,
-) -> Any:
- """
- Convert any object to something that can be encoded in JSON.
-
- This is used internally by FastAPI to make sure anything you return can be
- encoded as JSON before it is sent to the client.
-
- You can also use it yourself, for example to convert objects before saving them
- in a database that supports only JSON.
-
- Read more about it in the
- [FastAPI docs for JSON Compatible Encoder](https://fastapi.tiangolo.com/tutorial/encoder/).
- """
- custom_encoder = custom_encoder or {}
- if custom_encoder:
- if type(obj) in custom_encoder:
- return custom_encoder[type(obj)](obj)
- else:
- for encoder_type, encoder_instance in custom_encoder.items():
- if isinstance(obj, encoder_type):
- return encoder_instance(obj)
- if include is not None and not isinstance(include, (set, dict)):
- include = set(include)
- if exclude is not None and not isinstance(exclude, (set, dict)):
- exclude = set(exclude)
- if isinstance(obj, BaseModel):
- obj_dict = obj.model_dump(
- mode="json",
- include=include,
- exclude=exclude,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_none=exclude_none,
- exclude_defaults=exclude_defaults,
- )
- return jsonable_encoder(
- obj_dict,
- exclude_none=exclude_none,
- exclude_defaults=exclude_defaults,
- sqlalchemy_safe=sqlalchemy_safe,
- )
- if dataclasses.is_dataclass(obj):
- assert not isinstance(obj, type)
- obj_dict = dataclasses.asdict(obj)
- return jsonable_encoder(
- obj_dict,
- include=include,
- exclude=exclude,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_defaults=exclude_defaults,
- exclude_none=exclude_none,
- custom_encoder=custom_encoder,
- sqlalchemy_safe=sqlalchemy_safe,
- )
- if isinstance(obj, Enum):
- return obj.value
- if isinstance(obj, PurePath):
- return str(obj)
- if isinstance(obj, (str, int, float, type(None))):
- return obj
- if isinstance(obj, PydanticUndefinedType):
- return None
- if isinstance(obj, dict):
- encoded_dict = {}
- allowed_keys = set(obj.keys())
- if include is not None:
- allowed_keys &= set(include)
- if exclude is not None:
- allowed_keys -= set(exclude)
- for key, value in obj.items():
- if (
- (
- not sqlalchemy_safe
- or (not isinstance(key, str))
- or (not key.startswith("_sa"))
- )
- and (value is not None or not exclude_none)
- and key in allowed_keys
- ):
- encoded_key = jsonable_encoder(
- key,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_none=exclude_none,
- custom_encoder=custom_encoder,
- sqlalchemy_safe=sqlalchemy_safe,
- )
- encoded_value = jsonable_encoder(
- value,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_none=exclude_none,
- custom_encoder=custom_encoder,
- sqlalchemy_safe=sqlalchemy_safe,
- )
- encoded_dict[encoded_key] = encoded_value
- return encoded_dict
- if isinstance(obj, (list, set, frozenset, GeneratorType, tuple, deque)):
- encoded_list = []
- for item in obj:
- encoded_list.append(
- jsonable_encoder(
- item,
- include=include,
- exclude=exclude,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_defaults=exclude_defaults,
- exclude_none=exclude_none,
- custom_encoder=custom_encoder,
- sqlalchemy_safe=sqlalchemy_safe,
- )
- )
- return encoded_list
-
- if type(obj) in ENCODERS_BY_TYPE:
- return ENCODERS_BY_TYPE[type(obj)](obj)
- for encoder, classes_tuple in encoders_by_class_tuples.items():
- if isinstance(obj, classes_tuple):
- return encoder(obj)
- if is_pydantic_v1_model_instance(obj):
- raise PydanticV1NotSupportedError(
- "pydantic.v1 models are no longer supported by FastAPI."
- f" Please update the model {obj!r}."
- )
- try:
- data = dict(obj)
- except Exception as e:
- errors: list[Exception] = []
- errors.append(e)
- try:
- data = vars(obj)
- except Exception as e:
- errors.append(e)
- raise ValueError(errors) from e
- return jsonable_encoder(
- data,
- include=include,
- exclude=exclude,
- by_alias=by_alias,
- exclude_unset=exclude_unset,
- exclude_defaults=exclude_defaults,
- exclude_none=exclude_none,
- custom_encoder=custom_encoder,
- sqlalchemy_safe=sqlalchemy_safe,
- )
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/exception_handlers.py b/backend/.venv/lib/python3.12/site-packages/fastapi/exception_handlers.py
deleted file mode 100644
index 475dd7b..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/exception_handlers.py
+++ /dev/null
@@ -1,34 +0,0 @@
-from fastapi.encoders import jsonable_encoder
-from fastapi.exceptions import RequestValidationError, WebSocketRequestValidationError
-from fastapi.utils import is_body_allowed_for_status_code
-from fastapi.websockets import WebSocket
-from starlette.exceptions import HTTPException
-from starlette.requests import Request
-from starlette.responses import JSONResponse, Response
-from starlette.status import WS_1008_POLICY_VIOLATION
-
-
-async def http_exception_handler(request: Request, exc: HTTPException) -> Response:
- headers = getattr(exc, "headers", None)
- if not is_body_allowed_for_status_code(exc.status_code):
- return Response(status_code=exc.status_code, headers=headers)
- return JSONResponse(
- {"detail": exc.detail}, status_code=exc.status_code, headers=headers
- )
-
-
-async def request_validation_exception_handler(
- request: Request, exc: RequestValidationError
-) -> JSONResponse:
- return JSONResponse(
- status_code=422,
- content={"detail": jsonable_encoder(exc.errors())},
- )
-
-
-async def websocket_request_validation_exception_handler(
- websocket: WebSocket, exc: WebSocketRequestValidationError
-) -> None:
- await websocket.close(
- code=WS_1008_POLICY_VIOLATION, reason=jsonable_encoder(exc.errors())
- )
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/exceptions.py b/backend/.venv/lib/python3.12/site-packages/fastapi/exceptions.py
deleted file mode 100644
index 1a3abd8..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/exceptions.py
+++ /dev/null
@@ -1,246 +0,0 @@
-from collections.abc import Sequence
-from typing import Annotated, Any, Optional, TypedDict, Union
-
-from annotated_doc import Doc
-from pydantic import BaseModel, create_model
-from starlette.exceptions import HTTPException as StarletteHTTPException
-from starlette.exceptions import WebSocketException as StarletteWebSocketException
-
-
-class EndpointContext(TypedDict, total=False):
- function: str
- path: str
- file: str
- line: int
-
-
-class HTTPException(StarletteHTTPException):
- """
- An HTTP exception you can raise in your own code to show errors to the client.
-
- This is for client errors, invalid authentication, invalid data, etc. Not for server
- errors in your code.
-
- Read more about it in the
- [FastAPI docs for Handling Errors](https://fastapi.tiangolo.com/tutorial/handling-errors/).
-
- ## Example
-
- ```python
- from fastapi import FastAPI, HTTPException
-
- app = FastAPI()
-
- items = {"foo": "The Foo Wrestlers"}
-
-
- @app.get("/items/{item_id}")
- async def read_item(item_id: str):
- if item_id not in items:
- raise HTTPException(status_code=404, detail="Item not found")
- return {"item": items[item_id]}
- ```
- """
-
- def __init__(
- self,
- status_code: Annotated[
- int,
- Doc(
- """
- HTTP status code to send to the client.
- """
- ),
- ],
- detail: Annotated[
- Any,
- Doc(
- """
- Any data to be sent to the client in the `detail` key of the JSON
- response.
- """
- ),
- ] = None,
- headers: Annotated[
- Optional[dict[str, str]],
- Doc(
- """
- Any headers to send to the client in the response.
- """
- ),
- ] = None,
- ) -> None:
- super().__init__(status_code=status_code, detail=detail, headers=headers)
-
-
-class WebSocketException(StarletteWebSocketException):
- """
- A WebSocket exception you can raise in your own code to show errors to the client.
-
- This is for client errors, invalid authentication, invalid data, etc. Not for server
- errors in your code.
-
- Read more about it in the
- [FastAPI docs for WebSockets](https://fastapi.tiangolo.com/advanced/websockets/).
-
- ## Example
-
- ```python
- from typing import Annotated
-
- from fastapi import (
- Cookie,
- FastAPI,
- WebSocket,
- WebSocketException,
- status,
- )
-
- app = FastAPI()
-
- @app.websocket("/items/{item_id}/ws")
- async def websocket_endpoint(
- *,
- websocket: WebSocket,
- session: Annotated[str | None, Cookie()] = None,
- item_id: str,
- ):
- if session is None:
- raise WebSocketException(code=status.WS_1008_POLICY_VIOLATION)
- await websocket.accept()
- while True:
- data = await websocket.receive_text()
- await websocket.send_text(f"Session cookie is: {session}")
- await websocket.send_text(f"Message text was: {data}, for item ID: {item_id}")
- ```
- """
-
- def __init__(
- self,
- code: Annotated[
- int,
- Doc(
- """
- A closing code from the
- [valid codes defined in the specification](https://datatracker.ietf.org/doc/html/rfc6455#section-7.4.1).
- """
- ),
- ],
- reason: Annotated[
- Union[str, None],
- Doc(
- """
- The reason to close the WebSocket connection.
-
- It is UTF-8-encoded data. The interpretation of the reason is up to the
- application, it is not specified by the WebSocket specification.
-
- It could contain text that could be human-readable or interpretable
- by the client code, etc.
- """
- ),
- ] = None,
- ) -> None:
- super().__init__(code=code, reason=reason)
-
-
-RequestErrorModel: type[BaseModel] = create_model("Request")
-WebSocketErrorModel: type[BaseModel] = create_model("WebSocket")
-
-
-class FastAPIError(RuntimeError):
- """
- A generic, FastAPI-specific error.
- """
-
-
-class DependencyScopeError(FastAPIError):
- """
- A dependency declared that it depends on another dependency with an invalid
- (narrower) scope.
- """
-
-
-class ValidationException(Exception):
- def __init__(
- self,
- errors: Sequence[Any],
- *,
- endpoint_ctx: Optional[EndpointContext] = None,
- ) -> None:
- self._errors = errors
- self.endpoint_ctx = endpoint_ctx
-
- ctx = endpoint_ctx or {}
- self.endpoint_function = ctx.get("function")
- self.endpoint_path = ctx.get("path")
- self.endpoint_file = ctx.get("file")
- self.endpoint_line = ctx.get("line")
-
- def errors(self) -> Sequence[Any]:
- return self._errors
-
- def _format_endpoint_context(self) -> str:
- if not (self.endpoint_file and self.endpoint_line and self.endpoint_function):
- if self.endpoint_path:
- return f"\n Endpoint: {self.endpoint_path}"
- return ""
-
- context = f'\n File "{self.endpoint_file}", line {self.endpoint_line}, in {self.endpoint_function}'
- if self.endpoint_path:
- context += f"\n {self.endpoint_path}"
- return context
-
- def __str__(self) -> str:
- message = f"{len(self._errors)} validation error{'s' if len(self._errors) != 1 else ''}:\n"
- for err in self._errors:
- message += f" {err}\n"
- message += self._format_endpoint_context()
- return message.rstrip()
-
-
-class RequestValidationError(ValidationException):
- def __init__(
- self,
- errors: Sequence[Any],
- *,
- body: Any = None,
- endpoint_ctx: Optional[EndpointContext] = None,
- ) -> None:
- super().__init__(errors, endpoint_ctx=endpoint_ctx)
- self.body = body
-
-
-class WebSocketRequestValidationError(ValidationException):
- def __init__(
- self,
- errors: Sequence[Any],
- *,
- endpoint_ctx: Optional[EndpointContext] = None,
- ) -> None:
- super().__init__(errors, endpoint_ctx=endpoint_ctx)
-
-
-class ResponseValidationError(ValidationException):
- def __init__(
- self,
- errors: Sequence[Any],
- *,
- body: Any = None,
- endpoint_ctx: Optional[EndpointContext] = None,
- ) -> None:
- super().__init__(errors, endpoint_ctx=endpoint_ctx)
- self.body = body
-
-
-class PydanticV1NotSupportedError(FastAPIError):
- """
- A pydantic.v1 model is used, which is no longer supported.
- """
-
-
-class FastAPIDeprecationWarning(UserWarning):
- """
- A custom deprecation warning as DeprecationWarning is ignored
- Ref: https://sethmlarson.dev/deprecations-via-warnings-dont-work-for-python-libraries
- """
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/logger.py b/backend/.venv/lib/python3.12/site-packages/fastapi/logger.py
deleted file mode 100644
index 5b2c4ad..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/logger.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import logging
-
-logger = logging.getLogger("fastapi")
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__init__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__init__.py
deleted file mode 100644
index 620296d..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware import Middleware as Middleware
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index 4c6a3f8..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/asyncexitstack.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/asyncexitstack.cpython-312.pyc
deleted file mode 100644
index 5cc26d9..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/asyncexitstack.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/cors.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/cors.cpython-312.pyc
deleted file mode 100644
index 8274842..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/cors.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/gzip.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/gzip.cpython-312.pyc
deleted file mode 100644
index 9d6dc18..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/gzip.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/httpsredirect.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/httpsredirect.cpython-312.pyc
deleted file mode 100644
index ccd094a..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/httpsredirect.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/trustedhost.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/trustedhost.cpython-312.pyc
deleted file mode 100644
index 750b999..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/trustedhost.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/wsgi.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/wsgi.cpython-312.pyc
deleted file mode 100644
index 11e828e..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/__pycache__/wsgi.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/asyncexitstack.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/asyncexitstack.py
deleted file mode 100644
index 4ce3f5a..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/asyncexitstack.py
+++ /dev/null
@@ -1,18 +0,0 @@
-from contextlib import AsyncExitStack
-
-from starlette.types import ASGIApp, Receive, Scope, Send
-
-
-# Used mainly to close files after the request is done, dependencies are closed
-# in their own AsyncExitStack
-class AsyncExitStackMiddleware:
- def __init__(
- self, app: ASGIApp, context_name: str = "fastapi_middleware_astack"
- ) -> None:
- self.app = app
- self.context_name = context_name
-
- async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
- async with AsyncExitStack() as stack:
- scope[self.context_name] = stack
- await self.app(scope, receive, send)
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/cors.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/cors.py
deleted file mode 100644
index 8dfaad0..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/cors.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware.cors import CORSMiddleware as CORSMiddleware # noqa
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/gzip.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/gzip.py
deleted file mode 100644
index bbeb2cc..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/gzip.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware.gzip import GZipMiddleware as GZipMiddleware # noqa
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/httpsredirect.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/httpsredirect.py
deleted file mode 100644
index b7a3d8e..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/httpsredirect.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from starlette.middleware.httpsredirect import ( # noqa
- HTTPSRedirectMiddleware as HTTPSRedirectMiddleware,
-)
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/trustedhost.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/trustedhost.py
deleted file mode 100644
index 08d7e03..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/trustedhost.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from starlette.middleware.trustedhost import ( # noqa
- TrustedHostMiddleware as TrustedHostMiddleware,
-)
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/wsgi.py b/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/wsgi.py
deleted file mode 100644
index c4c6a79..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/middleware/wsgi.py
+++ /dev/null
@@ -1 +0,0 @@
-from starlette.middleware.wsgi import WSGIMiddleware as WSGIMiddleware # noqa
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__init__.py b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__init__.py
deleted file mode 100644
index e69de29..0000000
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/__init__.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/__init__.cpython-312.pyc
deleted file mode 100644
index bba387a..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/__init__.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/constants.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/constants.cpython-312.pyc
deleted file mode 100644
index e278ef3..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/constants.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/docs.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/docs.cpython-312.pyc
deleted file mode 100644
index 471c96c..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/docs.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/models.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/models.cpython-312.pyc
deleted file mode 100644
index 58855d9..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/models.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/utils.cpython-312.pyc b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/utils.cpython-312.pyc
deleted file mode 100644
index 904ff9a..0000000
Binary files a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/__pycache__/utils.cpython-312.pyc and /dev/null differ
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/constants.py b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/constants.py
deleted file mode 100644
index d724ee3..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/constants.py
+++ /dev/null
@@ -1,3 +0,0 @@
-METHODS_WITH_BODY = {"GET", "HEAD", "POST", "PUT", "DELETE", "PATCH"}
-REF_PREFIX = "#/components/schemas/"
-REF_TEMPLATE = "#/components/schemas/{model}"
diff --git a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/docs.py b/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/docs.py
deleted file mode 100644
index 82380f8..0000000
--- a/backend/.venv/lib/python3.12/site-packages/fastapi/openapi/docs.py
+++ /dev/null
@@ -1,344 +0,0 @@
-import json
-from typing import Annotated, Any, Optional
-
-from annotated_doc import Doc
-from fastapi.encoders import jsonable_encoder
-from starlette.responses import HTMLResponse
-
-swagger_ui_default_parameters: Annotated[
- dict[str, Any],
- Doc(
- """
- Default configurations for Swagger UI.
-
- You can use it as a template to add any other configurations needed.
- """
- ),
-] = {
- "dom_id": "#swagger-ui",
- "layout": "BaseLayout",
- "deepLinking": True,
- "showExtensions": True,
- "showCommonExtensions": True,
-}
-
-
-def get_swagger_ui_html(
- *,
- openapi_url: Annotated[
- str,
- Doc(
- """
- The OpenAPI URL that Swagger UI should load and use.
-
- This is normally done automatically by FastAPI using the default URL
- `/openapi.json`.
- """
- ),
- ],
- title: Annotated[
- str,
- Doc(
- """
- The HTML `
-
-
-
-
-
-